第一步,爬取并入库MySQL,这一步占了最多的时间,为了避免被Anti-Spider机制影响,所以限速也较低.

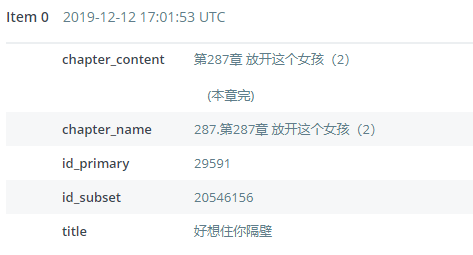
因为URL格式里面似乎包含了ID信息,所以也一并采集了.
![]()
第一段ID似乎是小说ID,第二段ID似乎是章节ID,章节ID和小说ID并非连续,但是同样的小说ID下,章节ID必然递增存在,所以储存时候就这么干.(正文内容省略)
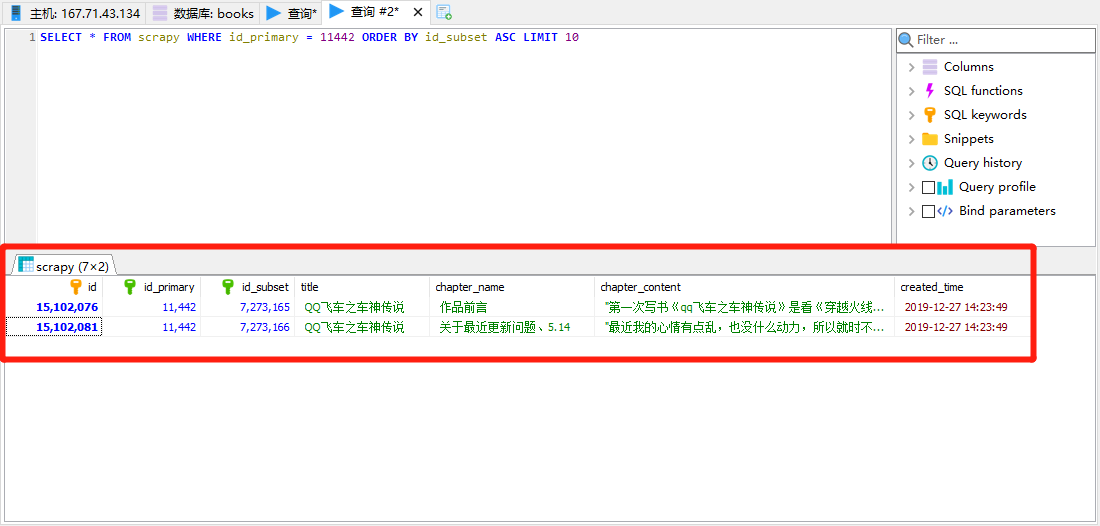
第二步就是得到CSV文件(大约100GB),然后从CSV文件入库,为什么不用pipeline入库的原因是数据库是临时用的,按需付费省着用.
CREATE DATABASE `books` use books; DROP TABLE `scrapy`; CREATE TABLE `scrapy` ( `id` INT NOT NULL AUTO_INCREMENT, `id_primary` INT NOT NULL, `id_subset` INT NOT NULL, `title` VARCHAR(200) NOT NULL DEFAULT '', `chapter_name` VARCHAR(200) NOT NULL DEFAULT '', `chapter_content` MEDIUMTEXT, `created_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP(), PRIMARY KEY (`id`), INDEX `id_subset` (`id_subset`), INDEX `id_primary` (`id_primary`) )ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; LOAD DATA LOCAL INFILE '/mnt/ScrapyBooks.csv' IGNORE INTO TABLE scrapy CHARACTER SET utf8mb4 FIELDS TERMINATED BY ',' LINES TERMINATED BY '\r\n' IGNORE 1 LINES (`chapter_content`,`chapter_name`,`id_primary`,`id_subset`,`title`); SHOW WARNINGS;
如果采集到的CSV 100G的话,入库大概需要170G的数据库空间,另外CSV文件需要处理,否则会被意外截断,前面已经有文章说过.
导入成功的最佳结果当然是0错误,0警告了.

第三步就是从数据库再提取回来,生成TXT文本的小说,当然,都入库了也可以用来生成网站.
import pymysql
def make( id ):
cursor = db.cursor()
sql = "SELECT * FROM scrapy WHERE id_primary = " + str(id) + " ORDER BY id_subset ASC"
cursor.execute(sql)
result = cursor.fetchone()
if result[3] == "":
print('似乎出现了书名不正确的情况')
print(result)
return
print('正在写入 ' + result[3] + '.txt')
wf = open('/mnt/volume_fra1_02/books/' + result[3] + '.txt','a')
#至少先做第一次提取,写入标题,然后检测标题是否在正文有重复,如果有重复,删除正文标题.
wf.write(result[4]+'\r\n')
content = result[5].replace(result[4],'')
wf.write(content.strip('"')+'\r\n'+'\r\n')
while result is not None:
result = cursor.fetchone()
if result is not None:
wf.write(result[4]+'\r\n')
content = result[5].replace(result[4],'')
wf.write(content.strip('"')+'\r\n'+'\r\n')
wf.close()
db = pymysql.connect(host="127.0.0.1",user="root",db="books",cursorclass = pymysql.cursors.SSCursor)
cursor = db.cursor()
sql = "SELECT DISTINCT id_primary FROM scrapy"
cursor.execute(sql)
id_dict = []
result = cursor.fetchone()
id_dict.append(result[0])
while result is not None:
result = cursor.fetchone()
if result is not None:
id_dict.append(result[0])
for tid in id_dict:
make(tid)
cursor.close()
db.close()
写入数据中...

打开检查,发现顺序正确,内容没问题.
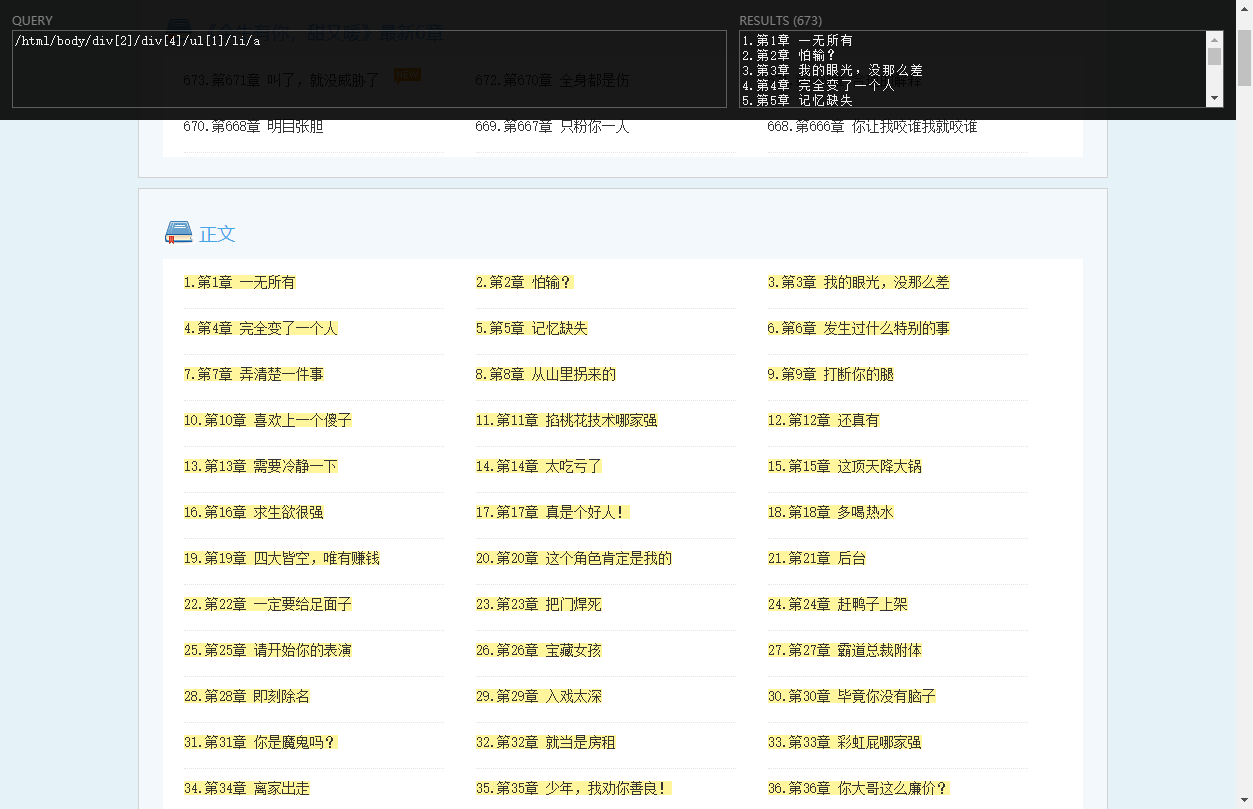
第四步,导出的文件总量大小约等于CSV文件大小(可能略大/略小),有些只有几MB,有些几十上百M,抽查发现有些提取出现问题,这个也是因为蜘蛛算法问题,看起来需要一些容错机制才行.
BUG举例:
导致原因,我用的XPATH提取了第一个ul,但是有些地方目录在第二个ul,所以出错了.
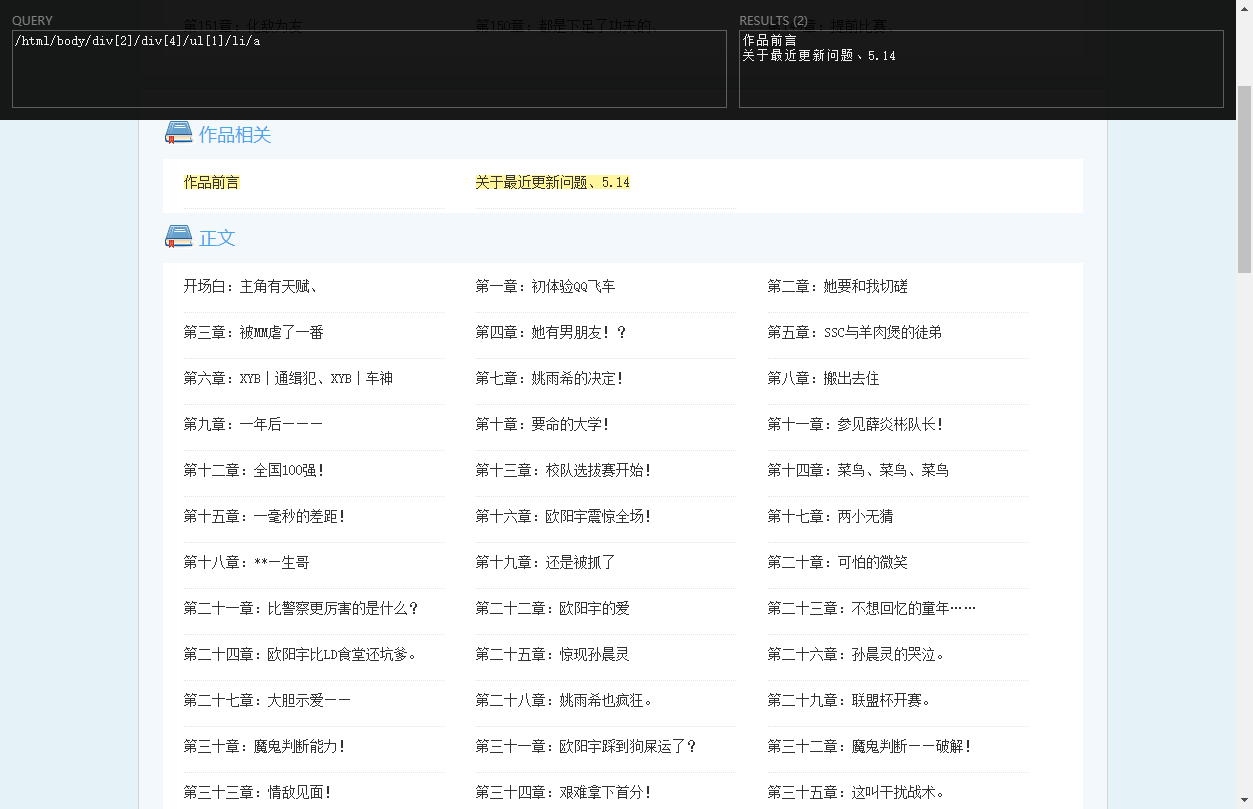
第一代含BUG爬虫先结束他,想搞第二代时候再说吧.