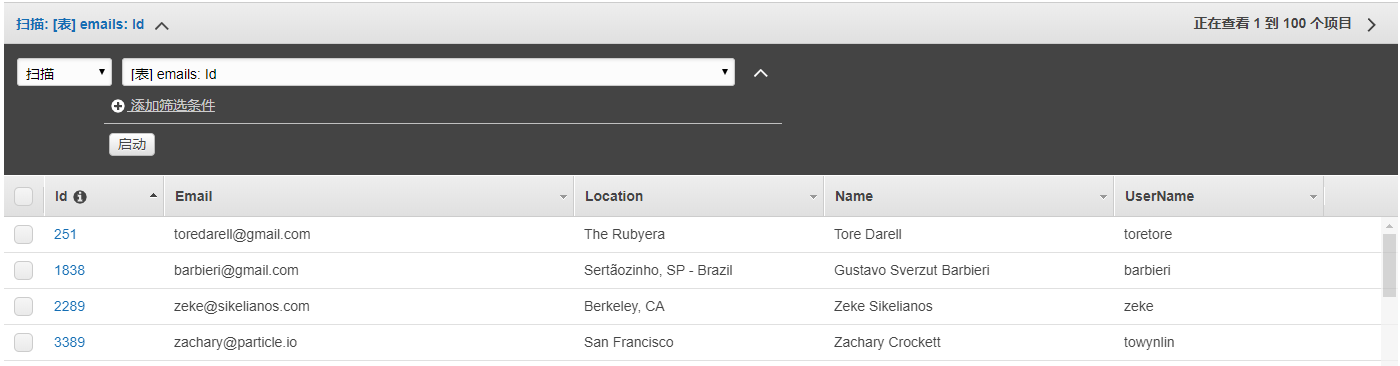
已知GitHub是需要填写一些用户数据(比如地点名字),可以通过API方式获取...
主要的获取策略:
指定一个大项目作者->列举他的所有repo->遍历每一个repo->遍历每一个repo里面的following->递归遍历每个follow的following(控制递归层数)
为了防止abuse,我就不放具体代码了,需要的可以自己完成...
下面是伪代码:
<?php require 'vendor/autoload.php'; ini_set('memory_limit', '-1'); $client = new Github\Client(); $client->authenticate('x', null, Github\Client::AUTH_HTTP_TOKEN);
$sdk = new Aws\Sdk([
'region' => 'us-east-1',
'version' => 'latest',
]);
$dynamodb = $sdk->createDynamoDb();
function following_users($name, $tag, $depth)
{
global $client;
$ram_usage = round(memory_get_usage() / 1024 / 1024,0);
$following_users = $client->api('user')->following($name);
foreach ($following_users as $following_user) {
$user = $client->api('user')->show($following_user['login']);
if ($client->api('rate_limit')->getResource('core')->getRemaining() < 10) { $sleep_time = $client->api('rate_limit')->getResource('core')->getReset() - time() + 60;
echo 'API 限流策略已触发,休息' . $sleep_time . '秒后继续采集.' . PHP_EOL;
sleep($sleep_time);
}
$response = $dynamodb->getItem();
// 如果这个Item已经存在,说明已经采集,否则可以入库.
if ($response['Item']['Id']['N'] != strval($user['id'])) {
// 这里需要处理入库的逻辑.
// 限制采集的最深层次,主要目的是防止内存消耗太多.(160MB内存足够几千层深度)
if ($ram_usage < 160) { // 递归到下一层 following_users($following_user['login'], $tag, $depth + 1); } } } } // 这个函数可以列特定repo的所有Fork和Watch function list_users($user, $repo) { global $client; $tag = $user . '/' . $repo; // Fork $networks = $client->api('repo')->forks()->all($user, $repo);
foreach ($networks as $network) {
following_users($network['owner']['login'], $tag, 0);
}
// Watch
$watchers = $client->api('repo')->watchers($user, $repo);
foreach ($watchers as $watcher) {
following_users($watcher['login'], $tag, 0);
}
}
// 这个函数列举某人下所有的repo
function list_repos($user)
{
global $client;
$repos = $client->api('user')->repositories($user);
foreach ($repos as $repo) {
list_users($user, $repo['name']);
}
}
// 从一个种子用户开始,通常选用比较牛逼的账号开始
list_repos('amazone');
exit(0);
正常来说,爬个几个月估计都停不下来,毕竟是递归,要把所有人爬完才会停了... 而且由于圈子的特性,你认识他可能他也认识,有不少重复的,所以入库效率就更低了.
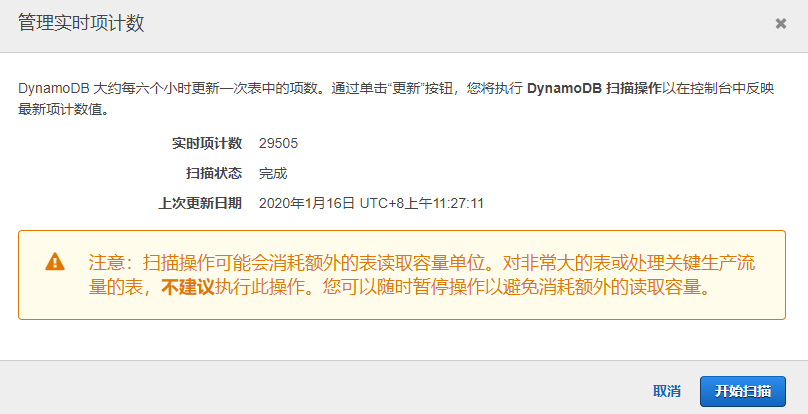
我自己写的采集的部分结果: