SIO是利用Cortex-M0的辅助总线IOPORT进行32B访问的,目的就是为了节约访问时间,做一些高速计算任务,也可以用于两个核心之间的通信.
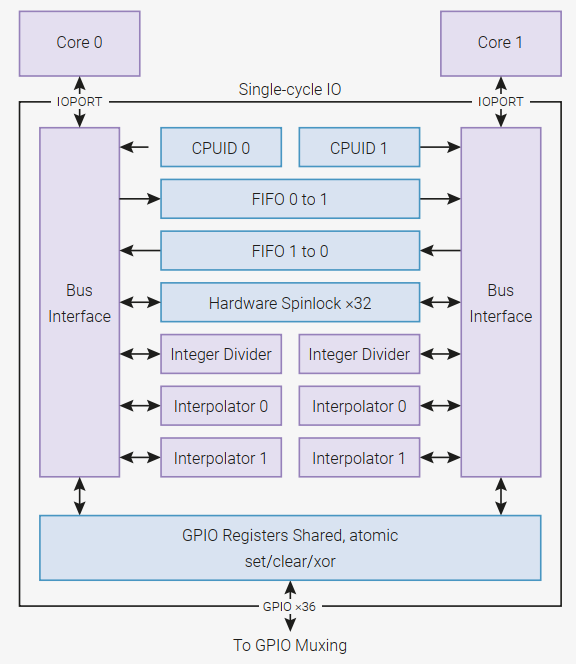
SIO的读写操作均为1个周期完成,最常用的就是双核心FIFO,互相交换数据,CPUID识别目前工作核心,硬件上的Mutex锁(这个外设在STM32H7上也有),读锁即Take,写锁即Give,硬件除法以及内插器,IO共享访问控制.实际上我们操作IO的时候,都经理了这些事情,对应的例子比较多,分别有Interpolator,HW divider,Multicore,而GPIO访问之前已经说了.
硬件除法器固定8个周期计算一次除法,得出余数和整数部分,根据我的理解,既然是余数,则应该不存在损失,只是可能不方便使用或表达.因为官方例子很简单,但是为了对比下优势,有必要做下速度测试.
divmod_result_t hw_result;
float sw_result = 0.0;
uint32_t start_time = 0;
uint32_t finish_time = 0;
float elapsed_time_s = 0.0;
uint32_t i = 0;
int main() {
stdio_init_all();
printf("Hello, divider!\n");
start_time = time_us_32();
for(i = 0;i < 100000000;i++){
hw_divider_divmod_s32_start(125, 30);
hw_result = hw_divider_result_wait();
}
finish_time = time_us_32();
elapsed_time_s = 1e-6f * (finish_time - start_time);
printf("HW Divider 100M Loop: %.3f s\n", elapsed_time_s);
start_time = time_us_32();
for(i = 0;i < 100000000;i++){
sw_result = 125 / 30;
}
finish_time = time_us_32();
elapsed_time_s = 1e-6f * (finish_time - start_time);
printf("SW Divider 100M Loop: %.3f s\n", elapsed_time_s);
return 0;
}测试结果出乎意料,为了8个周期释放CPU?但是似乎他和DMA没配合,所以究竟划算吗?由于是固定8个周期,所以是否带符号,速度是一样的.
Hello, divider!
HW Divider 100M Loop: 32.000 s
SW Divider 100M Loop: 16.000 s
接着看看Interpolator,每个处理器都有两个Interpolator,设计的本意是用来做音频处理的,但实际上可以做很多其他任务,可以在预配置的情况下,连续计算.处理器可以在一个周期内写入或读取任何一个累加器寄存器,下一个周期就可以得到结果.处理器还可以通过向相应的ACCUMx_ADD寄存器写入,对两个累加器ACCUM0或ACCUM1中的一个进行加法.围内,因为支持多种算法,实际上单独运行也没太大意义,所以也懒得展开了,运算的代码在GitHub和文档都有,这是运算结果.
Interpolator example
9 times table:
9
18
27
36
45
54
63
72
81
90
Masking:
ACCUM0 = 1234abcd
Nibble 0: 0000000d
Nibble 1: 000000c0
Nibble 2: 00000b00
Nibble 3: 0000a000
Nibble 4: 00040000
Nibble 5: 00300000
Nibble 6: 02000000
Nibble 7: 10000000
Masking with sign extension:
Nibble 0: fffffffd
Nibble 1: ffffffc0
Nibble 2: fffffb00
Nibble 3: ffffa000
Nibble 4: 00040000
Nibble 5: 00300000
Nibble 6: 02000000
Nibble 7: 10000000
Lane result crossover:
PEEK0, POP1: 124, 456
PEEK0, POP1: 457, 124
PEEK0, POP1: 125, 457
PEEK0, POP1: 458, 125
PEEK0, POP1: 126, 458
PEEK0, POP1: 459, 126
PEEK0, POP1: 127, 459
PEEK0, POP1: 460, 127
PEEK0, POP1: 128, 460
PEEK0, POP1: 461, 128
Simple blend 1:
500
582
666
748
832
914
998
Simple blend 2:
signed:
-1000
-672
-336
-8
328
656
992
unsigned:
0xfffffc18
0xd5fffd60
0xaafffeb0
0x80fffff8
0x56000148
0x2c000290
0x010003e0
Simple blend 3:
0x00004000
0x0000e800
0xffffe800
Clamp:
-1024 0
-768 0
-512 0
-256 0
0 0
256 64
512 128
768 192
1024 255
Linear interpolation:
0 (0% between 0 and 10)
2 (25% between 0 and 10)
5 (50% between 0 and 10)
7 (75% between 0 and 10)
10 (0% between 10 and -20)
2 (25% between 10 and -20)
-5 (50% between 10 and -20)
-13 (75% between 10 and -20)
-20 (0% between -20 and -1000)
-265 (25% between -20 and -1000)
-510 (50% between -20 and -1000)
-755 (75% between -20 and -1000)
-1000 (0% between -1000 and 500)
-625 (25% between -1000 and 500)
-250 (50% between -1000 and 500)
125 (75% between -1000 and 500)
Affine Texture mapping (with texture wrap):
0x00
0x00
0x01
0x01
0x12
0x12
0x13
0x23
0x20
0x20
0x31
0x31
最后最关键就是多核通信了,Pico是个双核芯片,在这个之前,一直都在单核跑,当然,实际上他可以双核运行的.先以hello_multicore来说明,核心0开机之后,立即启动核心1,核心1的代码为core1_entry,然后立即向FIFO PUSH一个标志,这时候核心0就收到PUSH的标志,然后等待的可以往下执行,同时核心0也往核心1 PUSH东西,然后核心1也能工作,当然,他们也可以独立工作,另外,需要在CMakeList下同时引用pico_multicore,这样才能起效果.
另外,由于FIFO里面存什么都可以,由因为他们共享一个代码空间,所以,也可以把函数任务动态地推送给核心1,即multicore_runner例子.
另外多核通信可以使用IRQ方式,这样不用一直blocking,FIFO总有8个槽深度,每个槽位都是32B的,要想两个核心之间通信就得利用FIFO,但是全局变量可以一起用,但是可能争抢导致奇怪的结果.
比如我修改简单的MultiCore代码.
#define FLAG_VALUE 123
uint32_t i = 0;
void core1_entry() {
multicore_fifo_push_blocking(FLAG_VALUE);
uint32_t g = multicore_fifo_pop_blocking();
if (g != FLAG_VALUE)
printf("Hmm, that's not right on core 1!\n");
else
i++;
printf("i = %d!\n",i);
while (1)
tight_loop_contents();
}
int main() {
stdio_init_all();
printf("Hello, multicore!\n");
///tag::setup_multicore[]
multicore_launch_core1(core1_entry);
// Wait for it to start up
uint32_t g = multicore_fifo_pop_blocking();
if (g != FLAG_VALUE)
printf("Hmm, that's not right on core 0!\n");
else {
multicore_fifo_push_blocking(FLAG_VALUE);
i++;
printf("i = %d!\n",i);
}
///end::setup_multicore[]
}运行结果如下:
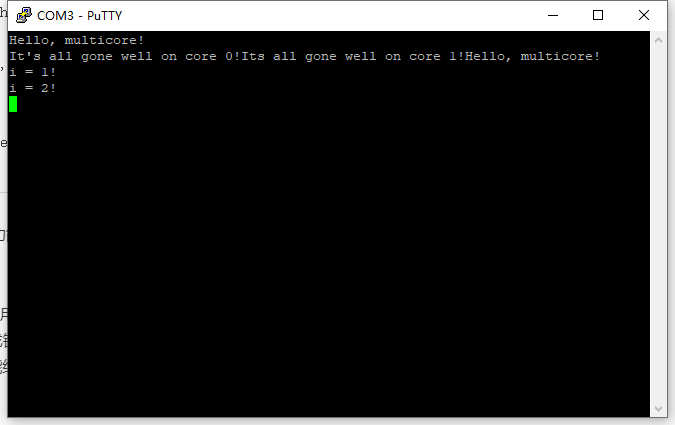
最后有一点,是例子没有的,即锁功能,官方把他做成头文件,变成信号量(SEM)和互斥(MUTEX)功能,以及他们的关键功能函数.
举个例子,用sem_init初始化,然后用sem_acquire_blocking获取,然后用sem_release释放信号量,因为信号量只有1和0,所以他们只有这个功能,把他理解成锁也是没问题的,和信号量有关的例子,参考WS2812就有.而Mutex不一样的是,Mutex解铃还须系铃人,就谁上的锁只能给谁解开,用起来和SEM差不多.