之前已经写过好些Tensorflow Lite Micro的内容,有一段时间没更新,主要是图像检测需要不少数据集来训练,然后一直没申请到数据集,自己准备数据集又没有那么多时间,那么只能用官方演示例子和官方数据集测试了,如果有条件最好还是自己准备数据集,大致就是拍某个东西的很多照片,然后给他们标记上.
注意:如果没看前面的内容,也没有基础,看不懂是正常的,请查找以前的内容看.
建议使用一台Ubuntu 20.04(尽量不使用衍生版,最好英文语言安装,避免各种兼容性问题.)宿主机,并且装好GPU驱动,CUDA库等等环境,然后做以下准备,我相信大家都有基础了,如果没有搜索TinyML关键字找到以前的内容看.
- Intel GPU Driver & CUDA (可选,只要你能忍受超慢的训练,这个可以不装!)
- Install ESP-IDF => https://github.com/espressif/esp-idf (确保idf.py可以使用.)
- Clone Tensorflow Repo => https://github.com/tensorflow/tensorflow (最好bazel构建一份同版本whl,获得最大兼容性.)
- ESP-IDF for Visual Studio Code => https://code.visualstudio.com (可选,你要有自己习惯的工具也行.)
切换到tensorflow目录,然后开始构建ESP32人体检测的范例.
make -f tensorflow/lite/micro/tools/make/Makefile TARGET=esp generate_person_detection_int8_esp_project切换到工作目录:
cd tensorflow/lite/micro/tools/make/gen/esp_xtensa-esp32_default/prj/person_detection_int8/esp-idf然后获取摄像头驱动:
git clone https://github.com/espressif/esp32-camera.git components/esp32-camera然后构建:
idf.py build # 构建工程,应该会失败.
rm build -rf # 删除构建临时文件有些文件索引不正确,最后会构建失败,但是这没关系,我们最终是要得到工程文件,把工程压缩后拉到本地Windows继续调试.(要是习惯Ubuntu也可以直接在Ubuntu继续,由于我安装的是无GUI版本,所以我只能拷贝过来方便.)
zip -r ~/esp.zip *最后在VSC打开工程应该长这个样子.
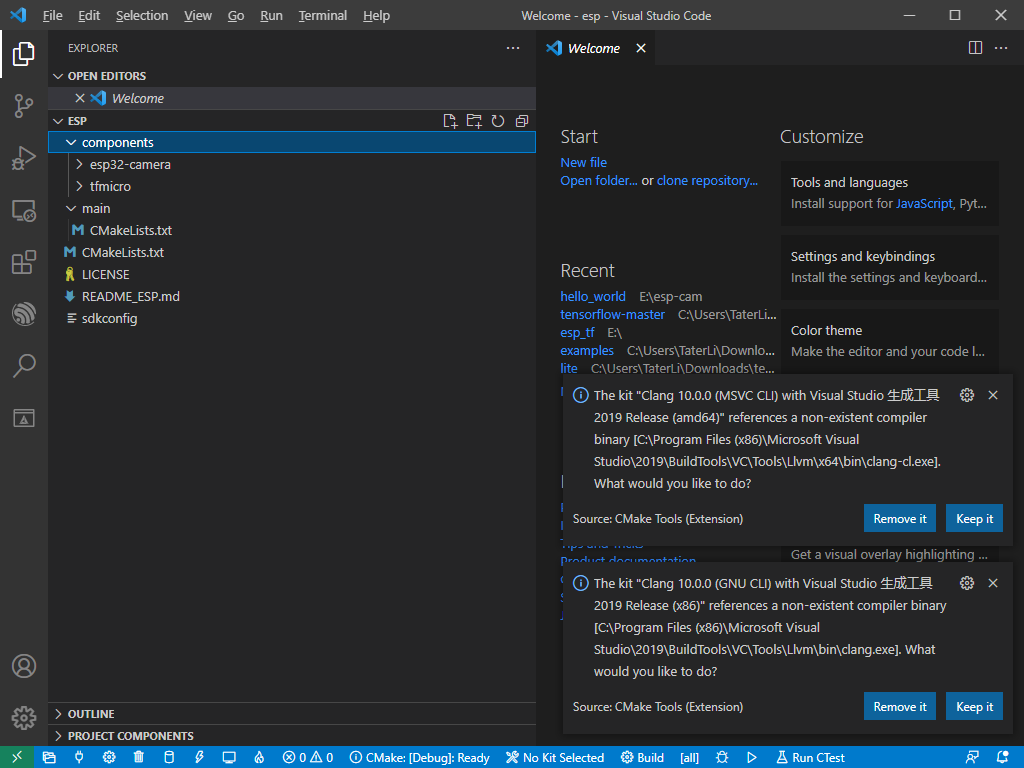
现在构建应该会各种丢失文件,但是也应该构建一次,丢什么补什么,然后image_provider要提供int8的数据,所以要改一下高亮的地方.
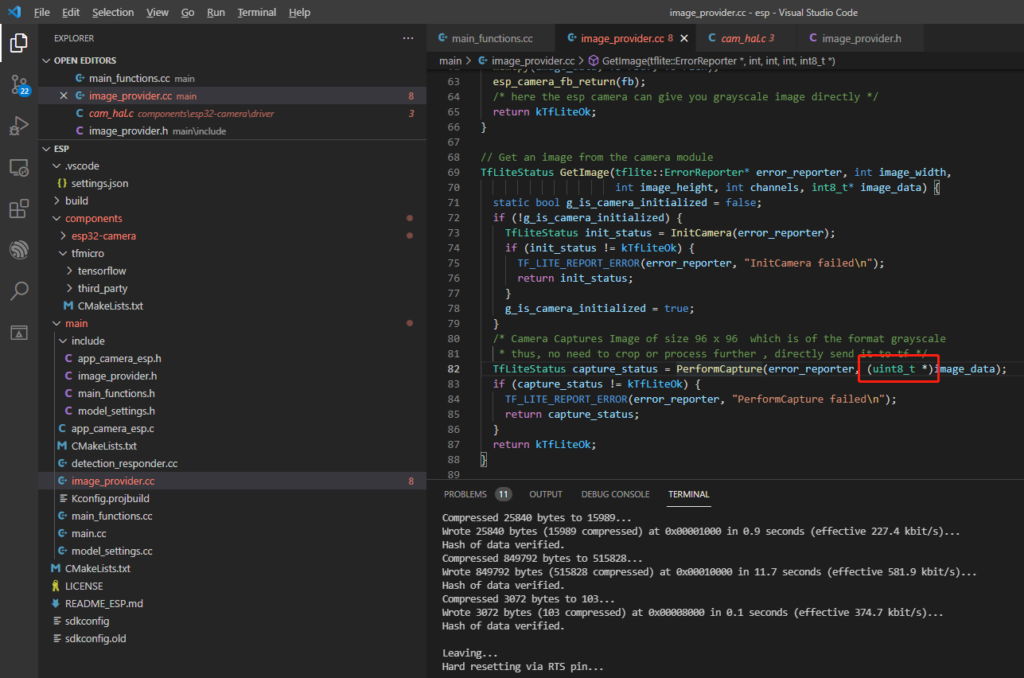
然后修改main/CMakeLists.txt内容:
#
# Main component of TF Micro project 'person_detection_int8'.
#
idf_component_register(
SRCS detection_responder.cc image_provider.cc main.cc main_functions.cc model_settings.cc app_camera_esp.c
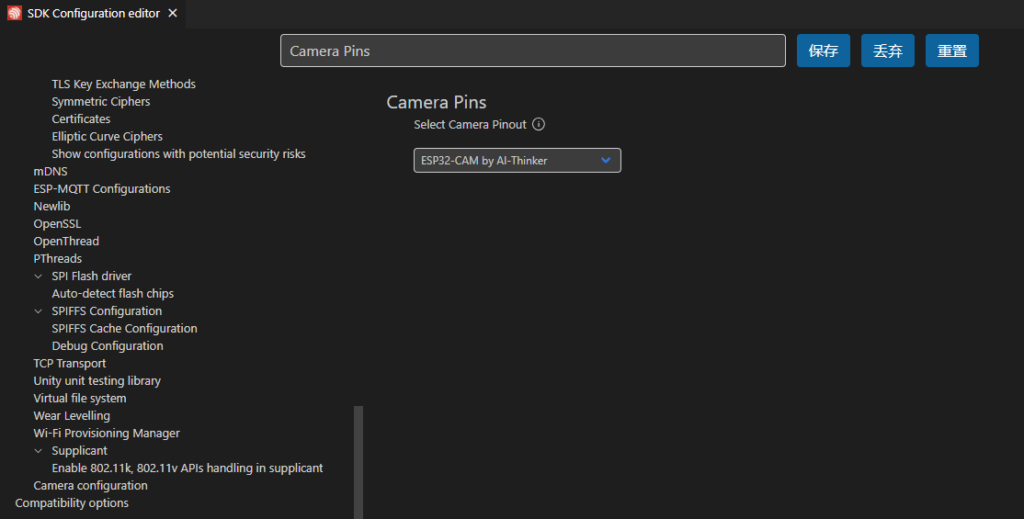
INCLUDE_DIRS "./include")然后修改摄像头配置,比如我用的就是安信可的模块:
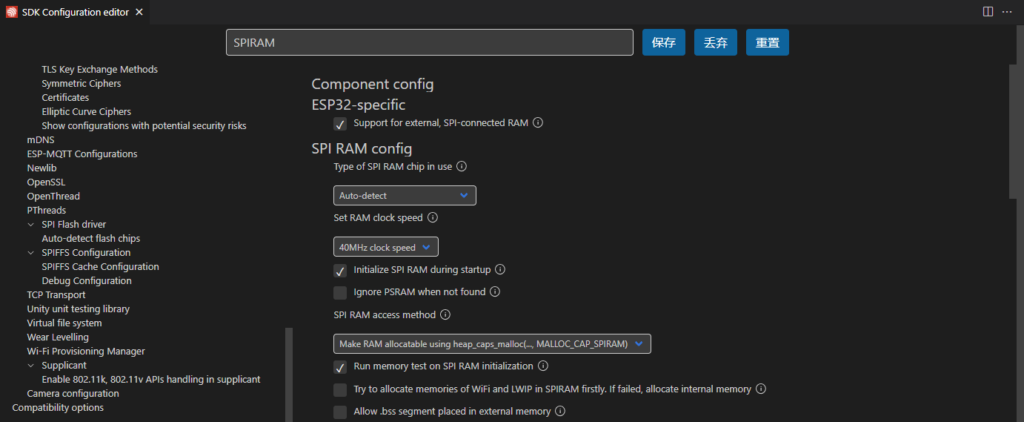
然后使能外部RAM并让malloc主动用外部RAM,如果需要还可以提高RAM的时钟频率(可能不稳定).
最后运营得出结果,当前面分数大于后面分数,代表检测到人.
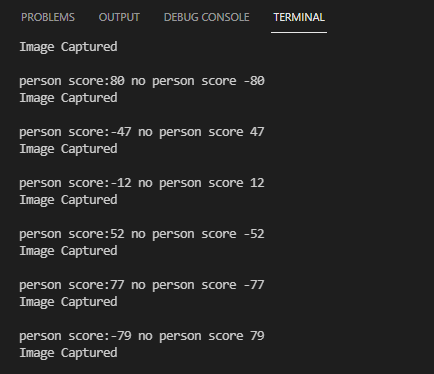
完整示例项目:https://github.com/nickfox-taterli/esp32-tf
注意:为什么没用单片机实现,主要是现在单片机价格也走高,估计还会走高一段时间,能跑摄像头还便宜的,目前应该就只有个这个方案了,含OV2640整板成本可以在20元以内,布板时候可以当他普通单片机用,WIFI部分都不做,输出结果用IO或者串口给另一个单片机或者他全跑完.
经过测试发现其准确率一般般,这是因为INT8本身就有损失,而且模型里面数据可能都是老外为主,所以有必要自己训练模型,你需要出去拍摄大量(数千张)各种各样人的照片,以及大量(数千张)不是人的照片,他们必须覆盖各种各样的环境,不能拍人都在室内,拍物体都在室外,这样会给出很大的误解.
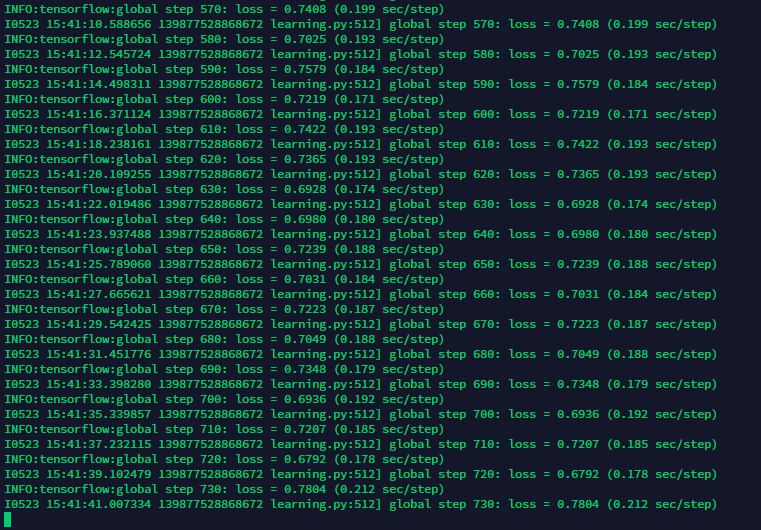
我这里大致说下训练,这里用的CPU训练,如果你有GPU就不要开clone_on_cpu开关,并且步数设置到足够多,比如10万,20万步,因为CPU速度很慢,所以我设置了1000步仅作测试,准确度更加低.
python3 download_and_convert_data.py --dataset_name=visualwakewords \
--dataset_dir=/mnt/data/visualwakewords
python3 train_image_classifier.py --train_dir=/mnt/vww_96_grayscale \
--dataset_name=visualwakewords \
--dateset_split=train \
--dataset_dir=/mnt/data/visualwakewords \
--model_name=mobilenet_v1_025 \
--preprocessing_name=mobilenet_v1 \
--train_image_size=96 \
--use_grayscale=True \
--save_summaries_secs=300 \
--learning_rate=0.045 \
--label_smoothing=0.1 \
--learning_rate_decay_factor=0.98 \
--num_epochs_per_decay=2.5 \
--moving_average_decay=0.9999 \
--batch_size=96 \
--max_number_of_steps=1000 \
--clone_on_cpu=True学习过程,由于每步都要几秒,学习完也要几个小时了.
数据是由很多图片和一个描述JSON组成,抽取部分数据来看.

如果要做自己的COCO数据集,有很多可用的工具,比如这个就说的很明白:https://patrickwasp.com/create-your-own-coco-style-dataset/
最后得到很多checkpoint文件,然后按照之前教程所说转换并移植过去就行.
最后如果对TPU有兴趣,可以试试更大的数据集,看看谷歌的教程(COCO不需要申请,ImageNet需要申请,并且数量更大.):https://cloud.google.com/tpu/docs/imagenet-setup?hl=zh-cn