其实这两个名字说的是同一个东西,但是不同的地方都有不同的介绍,在传输层最常见也是和我们日常生活最相关的就是TCP和UDP协议,包括我们网络配置的BGP也是基于TCP协议,我们查看维基百科的知名端口号,也能看得出来大致哪些日常生活常用协议,我这里只截图了部分.
https://zh.wikipedia.org/wiki/TCP/UDP%E7%AB%AF%E5%8F%A3%E5%88%97%E8%A1%A8
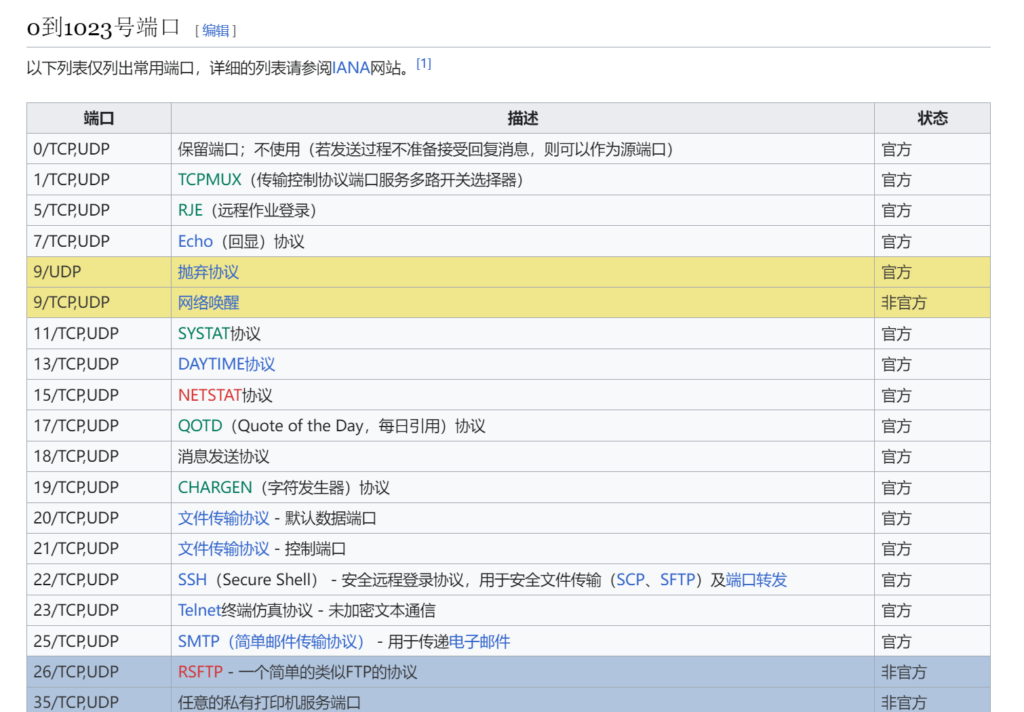
还有一些不属于TCP/UDP的,但是也用到传输层的,比如OSPF协议(https://www.ietf.org/rfc/rfc2328.txt),协议号是89,所以不要再问OSPF用什么端口了,人家也不依赖什么端口,但确实属于运输层协议.而这么多协议中,最多应该说的就是TCP协议,因为UDP的传输保证和逻辑依赖应用层来实现.
我们一开始就说过,下层为上层提供服务,运输层是承载在网络层上方,所以讨论运输层时候,默认网络层已经是正常的了,在网络层我们有多播和广播,而这个不能在TCP这种握手协议上用,毕竟你也不可能同时握手很多人,UDP是可以的,比如直播推流这些基本都是UDP,当然前面说到的OSPF也可以,但是这里主要讨论TCP/UDP,后面就默认只有这么两个了.
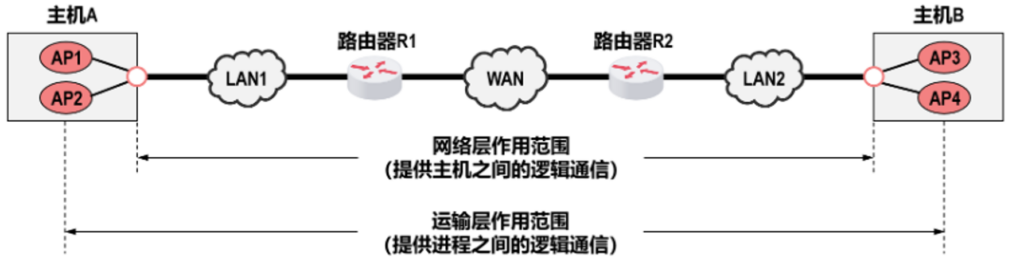
TCP实现比UDP复杂,TCP提供连接管理,确认机制,超时重传,流量控制,拥塞控制,并且通信前要建立链接,通信完要关闭链接,而UDP就是什么都没实现,能收到就收,收不到就算.
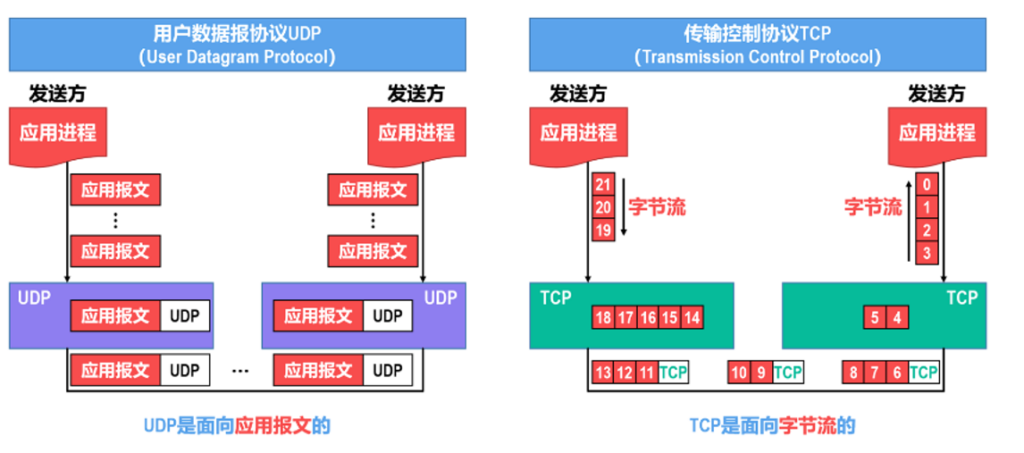
我们之前的网络层讲的都是一个IP地址到另一个IP地址,但是我们实际是一个应用到另一个应用,所以为了区分不同应用通信,引入了端口的概念,端口的范围是0-65535,其中0-1023是熟知端口,我们开发自定义软件时不应该使用这些端口,1024-49151是登记端口,我们推荐使用这个范围还没被官方保留的端口,49152-65535一般是临时端口,系统在需要时候会临时申请使用,系统会在用户不再使用时自动回收.
下面举例这个UDP传输,UDP的头部中只有源端口,目标端口,校验和,然后剩下就是携带的信息,属于应用层管的范围了.
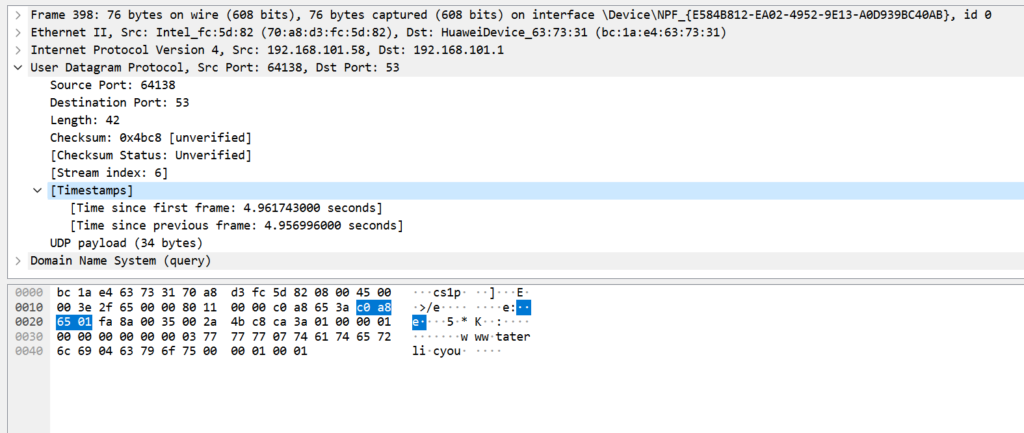
TCP/UDP的校验和都是要加上伪首部进行计算的,这样的话能同时校验数据来源的正确性,TCP和UDP计算方法基本一样,唯一就是协议字段,TCP是6,UDP是17.
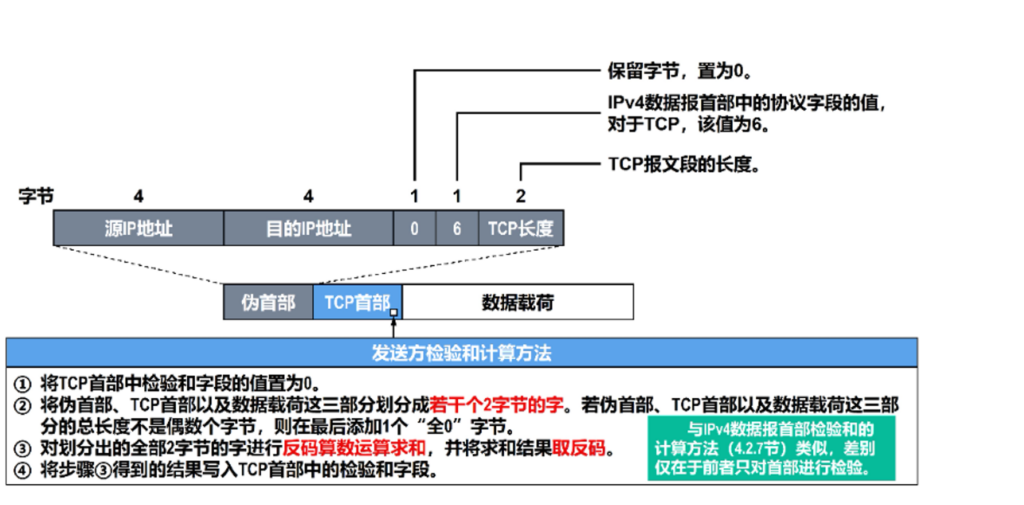
TCP头则比较复杂.
从抓包软件里也能看到明显差别.
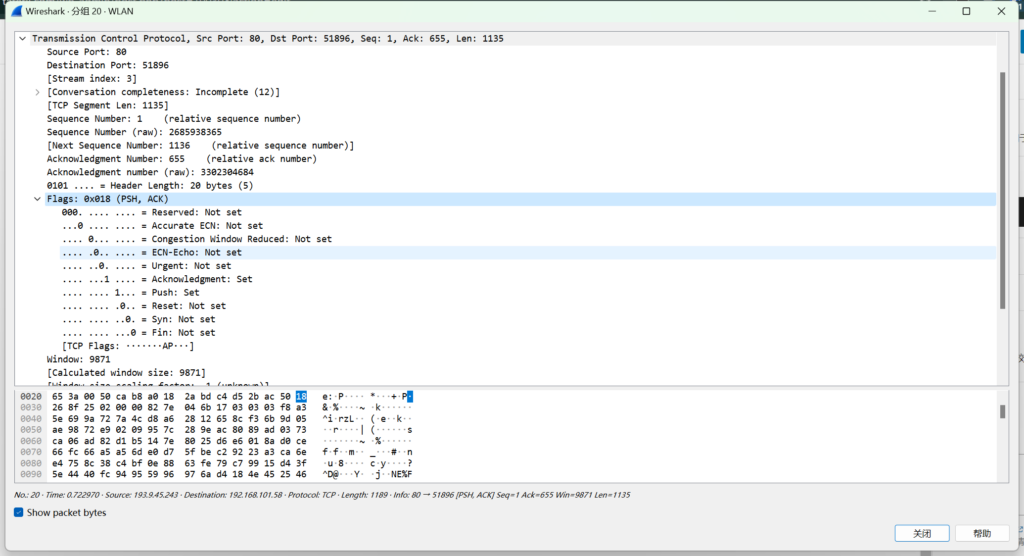
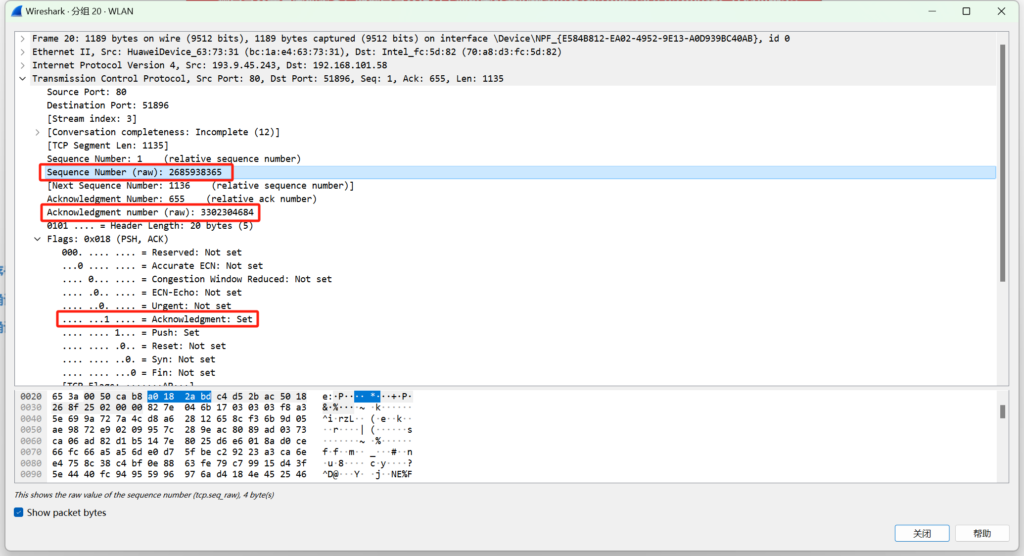
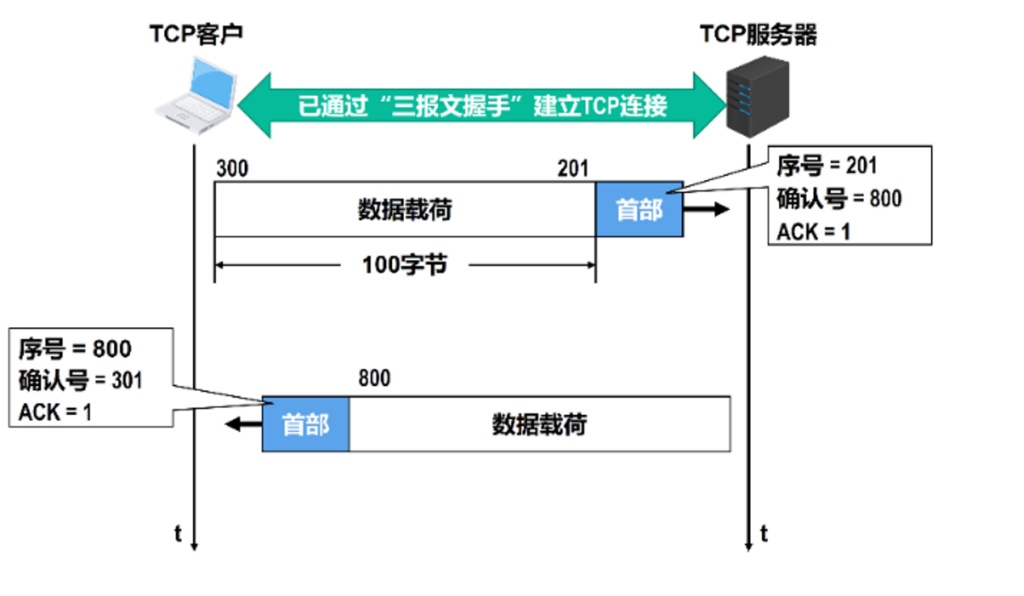
TCP可靠传输最重要手段就是传输确认,如下图给出的序号,确认号都是以字节为单位,当计算到2^32-1最大值时候会绕回,但是由于双方都有时间戳,所以一般没问题,而且也不可能数个RTT中就绕回.
- 序号用来指出本TCP报文段数据载荷的第一个字节的序号.
- 确认号必须在ACK=1时才有效,正常传输的TCP数据都是ACK的,他用来指出期望收到对方下一个TCP报文段的数据载荷的第一个字节的序号,同时也是对之前收到的数据进行确认.
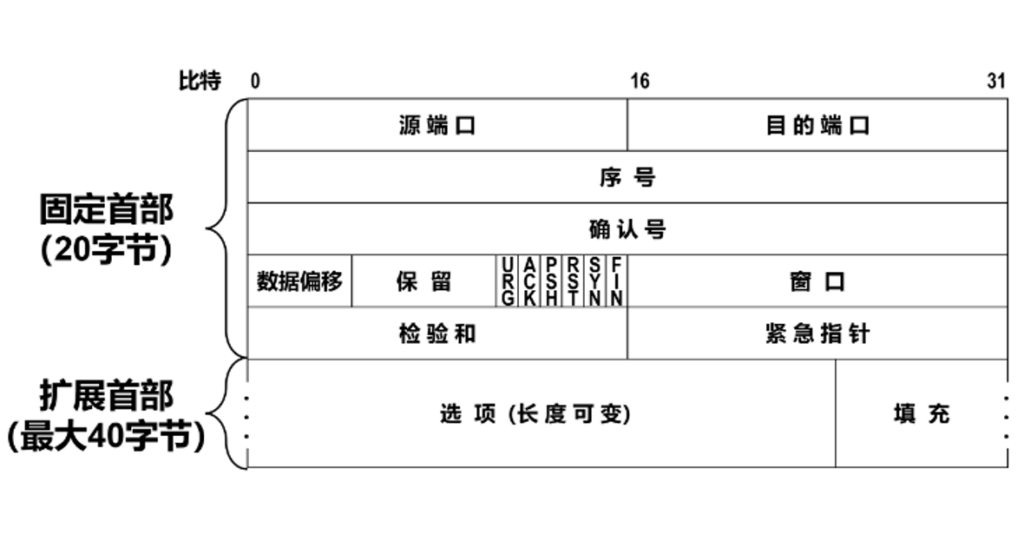
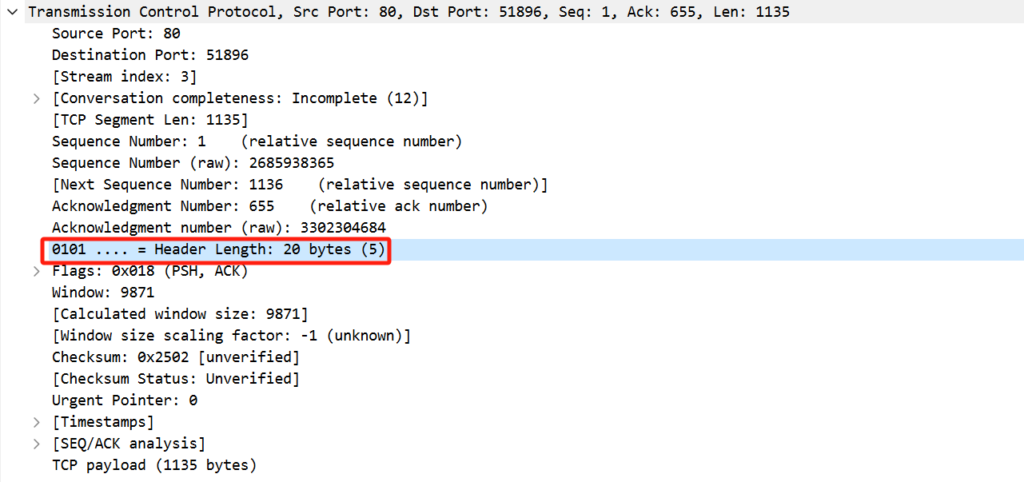
数据偏移也叫头部长度,因为TCP头部长度是不固定的,他是以4字节为单位,如果头部长度不够4字节就要自动补全到4的倍数,比如我这个数据包的头部是20字节,是最小的TCP头部,只包含必须的信息,有些TCP头可能包含选项字段,比如约定调整MSS,时间戳传输,选择确认(SACK)等等,没有固定功能.
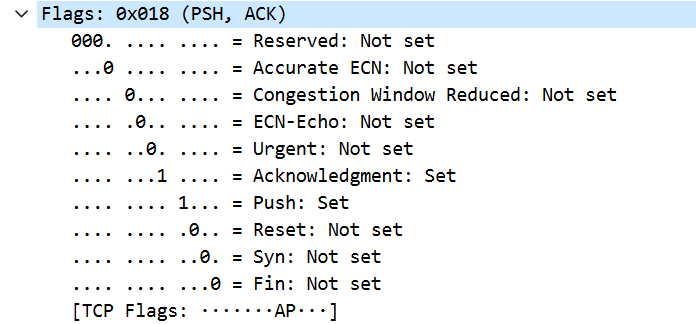
保留字段在Wireshark中没显示,他也占用了6比特,目前还没实现任何功能.下面的窗口字段,即9871这个,是根据TCP传输质量自动调整,用于流量控制,后面会单独讲到,这个相当复杂.
标志位有很多作用.
- 当SYN=1,ACK=0时,这是TCP请求链接,当对方同意,则需要回复SYN=1,ACK=1,所以SYN只在请求链接和回复链接时有用.
- FIN=1代表数据全部发完了,这次的TCP链接也要释放了.
- RST=1表示强行复位当前TCP链接,这个我们应该也看到不少,一般在严重差错或者特殊原因下会得到RST或者发出RST标志.
- PSH=1表示数据要马上Push出去,不要等累计够数量才发.
- URG=1代表数据紧急,需要插队处理,当到达多个数据报时,URG=1的数据包会被提前取出.
- 其他标志主要是网络控制功能,并不常用.
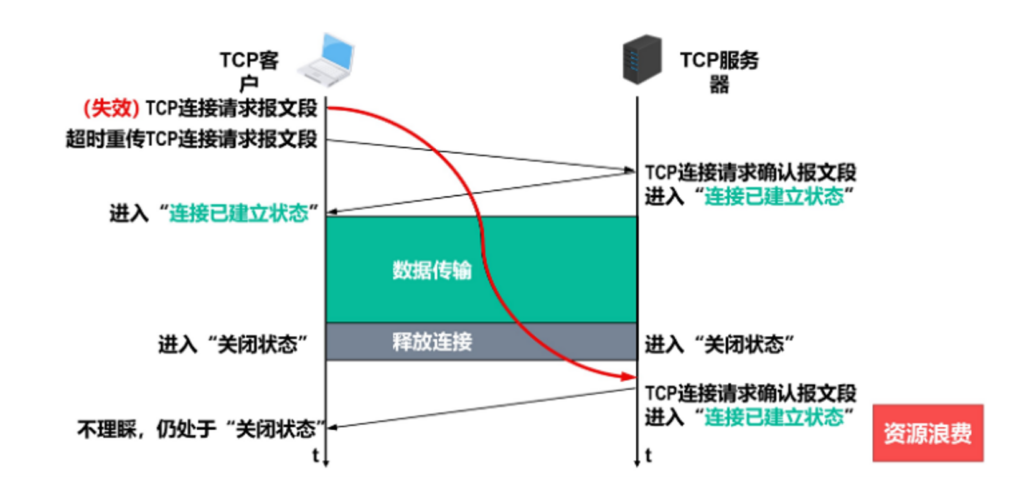
TCP建立链接需要握手,这个网上到处都有说,这里不展开,这里说一下为什么不能采用两段握手,主要是防止已失效的TCP链接请求报文突然又传到了TCP服务器进程,导致错误,比如这里发送了两次TCP请求握手,因为其中一个是超时重传的,但是之前超时的那个只是到了一个很拥堵的路由器,他后面又突然到了,这就出问题了.
TCP断开链接挥手也是网上非常多内容在写了,这里也讨论一下为什么断开要等待2MSL,第一是保证FIN-WAIT-2最后的确认报文一定能到,如果没到就重发,这就是时间,不重发永远不倒,服务器得等到几个小时后主动查询发现断开了才能释放.等待2MSL时间,可以确保网络中所有报文都传递完毕.(MSL在RFC793建议是2分在,2MSL就是4分钟,MSL即最长报文寿命)
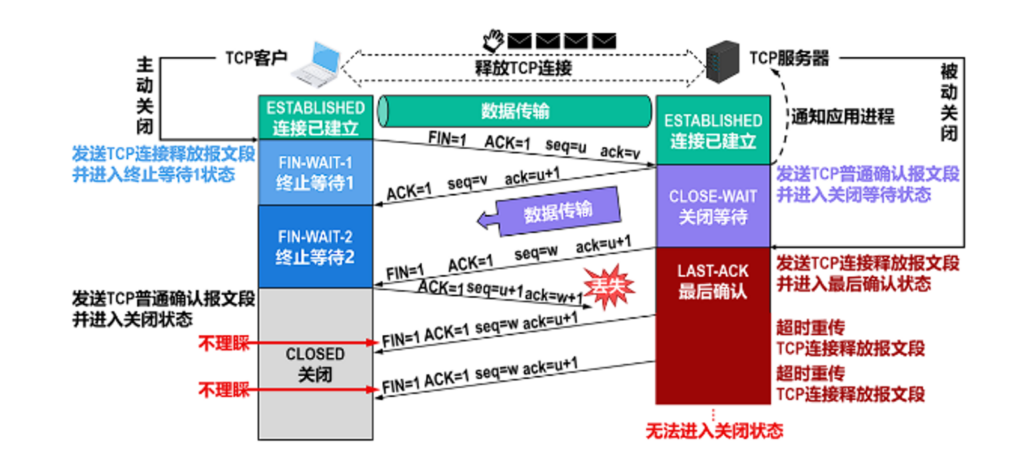
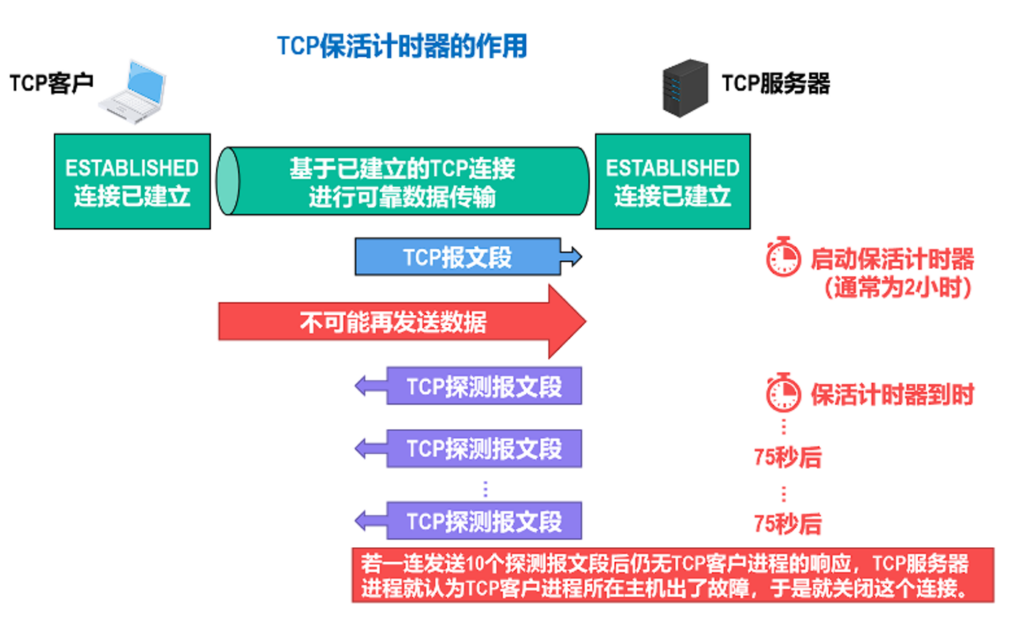
如果2MSL依然没关闭,这个可能性很少了,更多可能是客户端突然下线(比如断电断网),也有TCP保活计时器进行自动释放.
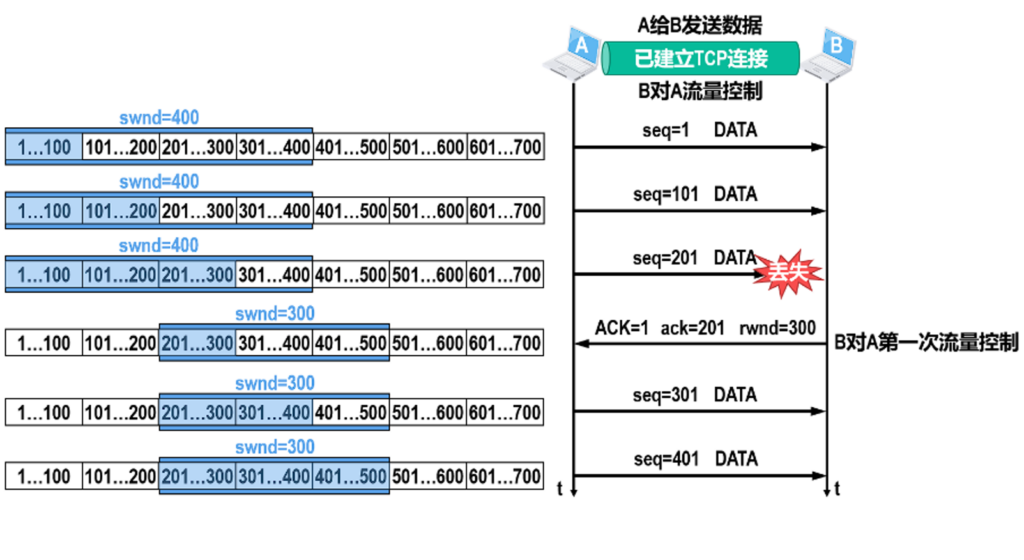
TCP传输中还有两大难点,流量控制和拥塞控制.
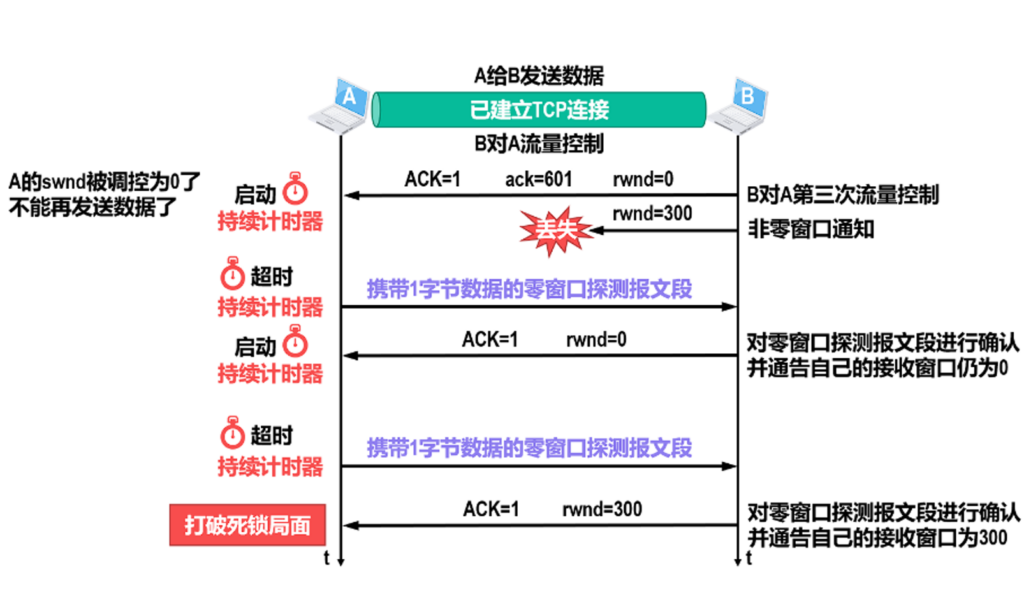
当一段较为繁忙时,会缩小接收窗口.
当B端实在太忙,缩小为0了,那A就不能发送正常报文给B.
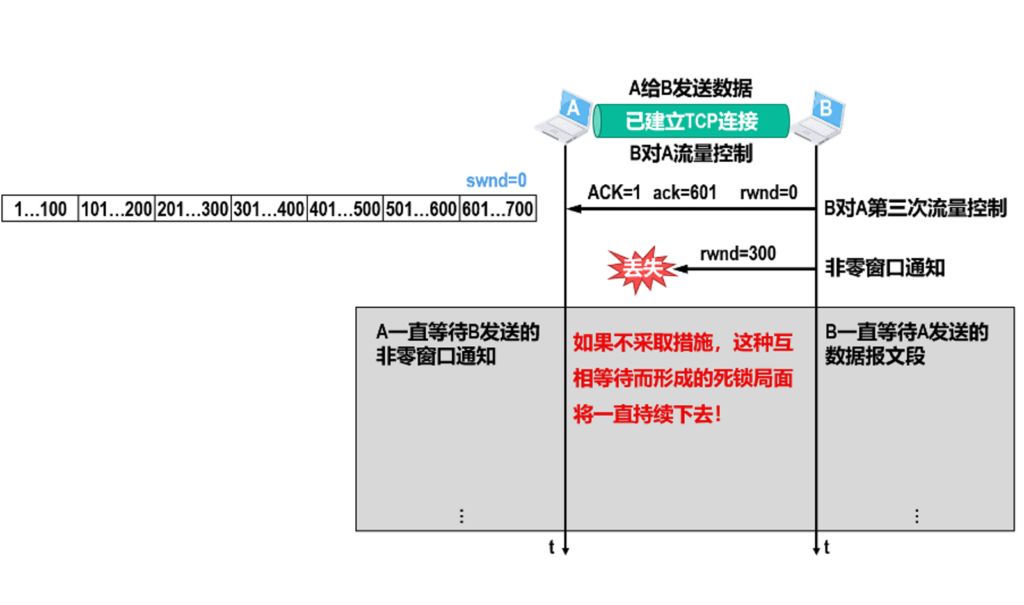
A端要定期采取询问措施,直到B端回复有能力处理了,就算询问报文丢失也没关系,因为他是周期性询问的.
拥塞控制就是尽可能最大化网络利用效率的一个方法,因为网络通常是复杂的,我们常说的bbr这就是比较新的一种拥塞控制方法,可见拥塞控制可以提升传输效率,拥塞控制没有一个固定的规范,一般我们认为要很亮一个传输质量可以从以下几点来看.
- 路由器的平均队列长度
- 超时重传比例
- 缓冲区溢出比例
- 分组的延迟
- ....
由于拥塞发生位置非常多,也没有一个好的方法让路由器或者远端准确反馈拥塞情况,所以TCP基本是靠RTT和其他信息推断拥塞情况的,当然拥塞控制也是有开销的,但是这些开销属于值得的.
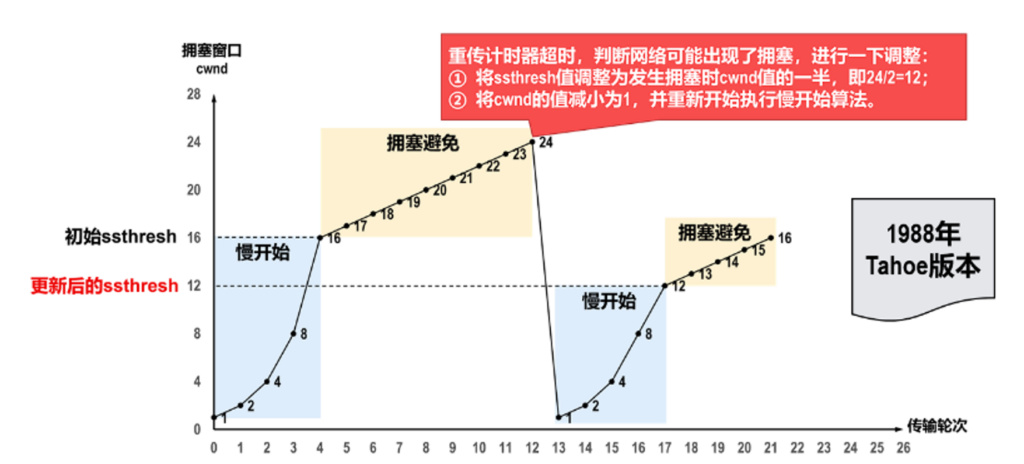
古老的Tahoe算法,先估算一个初始的ssthresh,比如图中的16,慢开始第一刻发送1数据报,然后2数据报,4数据报每次都翻倍,直到达到ssthresh之后,每次只增加1数据报,直到发送重传,之后更新ssthresh为丢包时的一半,然后发送窗口从1开始重新进行慢开始,最后得到比较平衡的ssthresh.
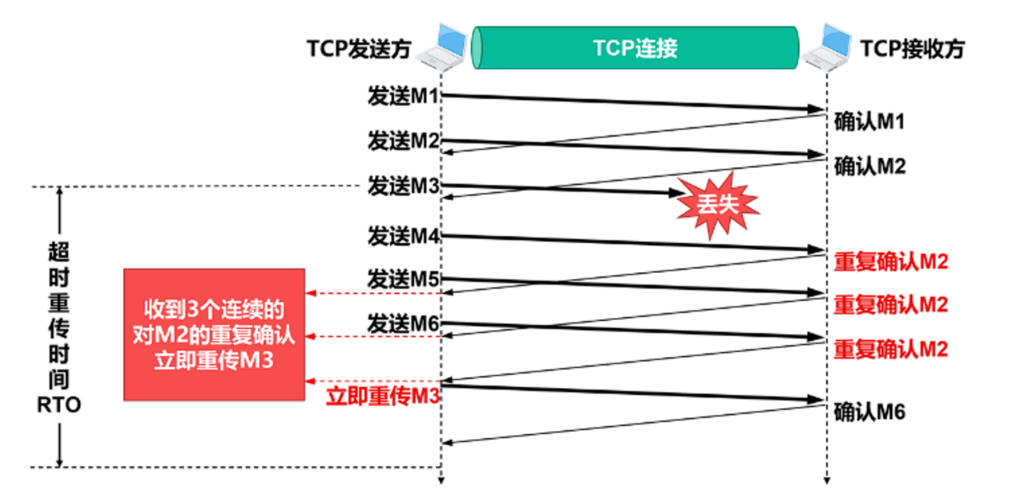
后面还有快恢复算法,如果发送方收到连续三个确认号都是以前的信息,那么立即重传,而不等待RTO定时器.
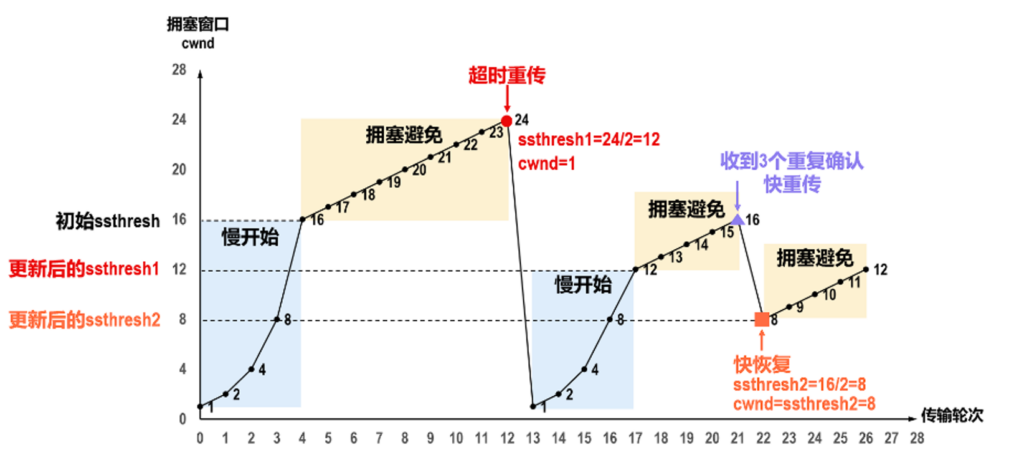
快重传和快恢复是配合一起用的,其算法逻辑参考下图的后半部分,一开始也是慢开始,收到三个重复确认则马上重传,并更新ssthresh,当然如果没收到三个重复确认,那就等同于这个图前半部分.
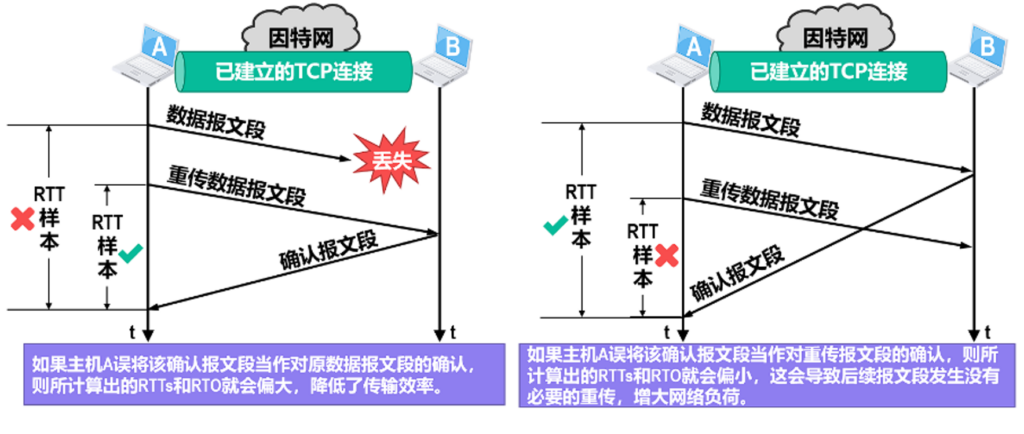
为什么会出现数据报没到达的情况,可能是途中某些路由器比较繁忙,或者是某些路由器实现AQM时,发现自己可能马上扛不住了就随机丢一些包,这样让发送方和接收方都知道线路有点忙了,那么何时重传,因为每次数据包的RTT都不固定,有时候网络没那么拥堵就很快,有时候拥堵很厉害就很慢,所以都要采集多个RTT进行计算,然后RTO只要比一般RTT高一点点就是最好的,这样不会造成滥发也不会导致太久才重发.


对于有重发的样本不纳入统计可能是更方便的.
前面说到还可以用SACK选项字节,捎带确认等等来改善拥塞控制,这些应用要不不太广泛,要不就比较复杂,这些还是看网上专家们的分析了.
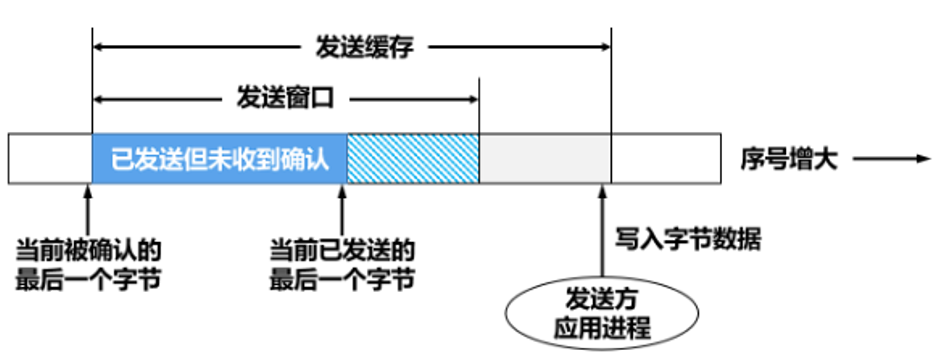
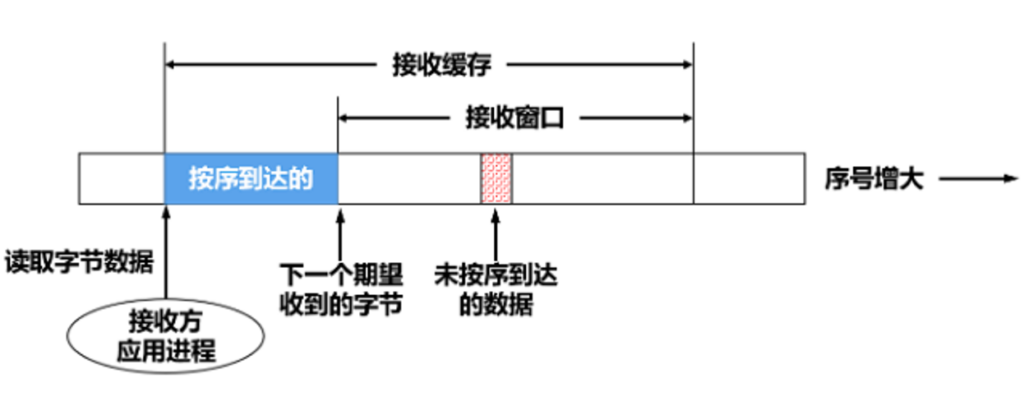
数据发送就有一个发送缓冲区,数据接收就有接收缓冲区,发送窗口一定会小于或者等于发送缓冲区,接收同理,缓冲区是应用层开辟的给传输层使用的一个临时地方.
发送缓冲区.
接收缓冲区.
就像前面说的流量控制一样,TCP传输窗口也是可靠传输控制的一环.发送窗口和接收窗口大小不一定是等大的,如果用到了SACK,那么要协商是否支持,TCP传输是全双工的,所以为了方便讨论,我们先讨论一个方向,实际上各自都是收发双方,各自都有发送接收窗口.假设发送方的窗口里是字节序号31-字节序号50都是可以发送的,现在接收方没收到31的数据,但是收到了32和33这两个序号的数据.
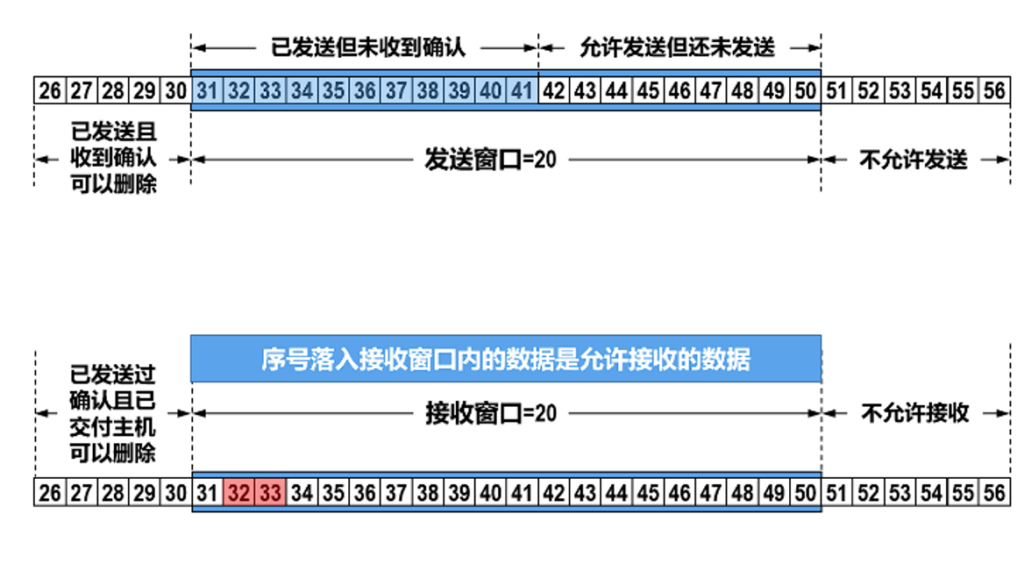
接收方希望接收31,我自己的接受窗口依然是20.
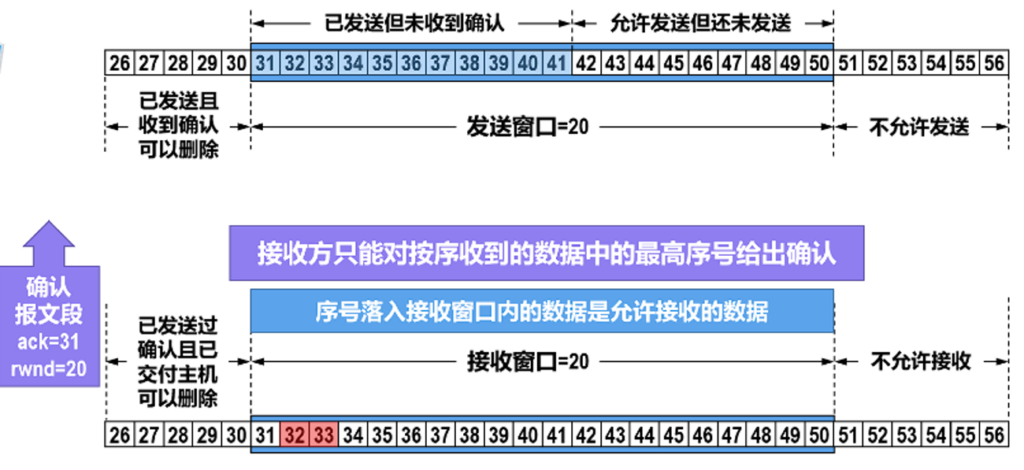
发送方把31发过来,接收确认就为34了.

发送窗口只有在接收完全确认后才会移动,当然这是现行标准,以后可能也许会改变,这样一直确认,直到数据全部发送完成.