如下图,就可能会被意外截断.
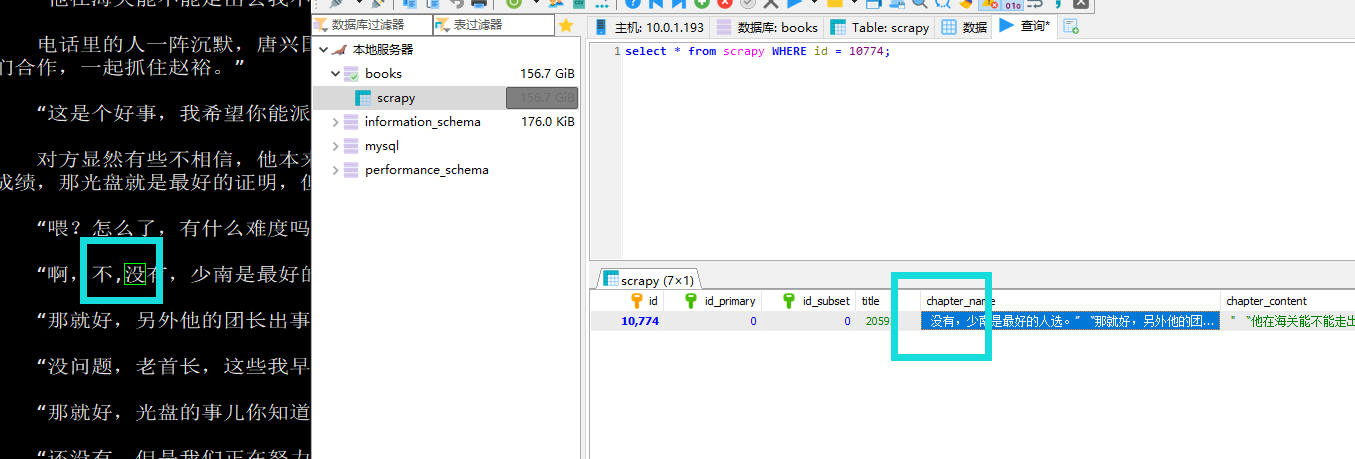
还有就是导入完毕有这样的警告,也有可能是截断错误.(当然也有可能字段太小)
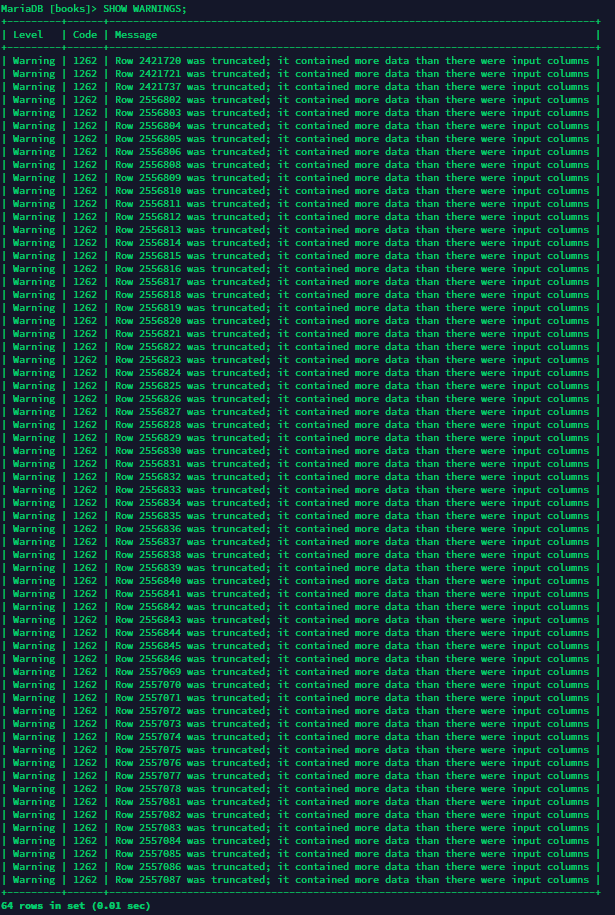
想到的解决办法有几个.
- 用JSON保存爬虫数据,但是导入MySQL需要自己处理.
- 在爬取时候替换逗号为中文逗号,会降低爬虫效率.
- 边爬取边入库,会使用数据库资源,成本高.
- 对现有CSV文件进行处理,用Python MySQL方式入库,入库效率较低.
- 对现有CSV文件处理,然后修改替换入库,效率最高,任务分离,我选择这种方法.
要对标题,章节标题,内容进行逗号替换.
代码如下,
import csv
import sys
csv.field_size_limit(sys.maxsize)
with open('./ScrapyBooks-all.csv', newline='', encoding='utf-8') as f,open('./ScrapyBooks-new.csv', 'w', newline='', encoding='utf-8') as wf:
reader = csv.reader(f)
writer = csv.writer(wf)
for row in reader:
row[0] = row[0].replace(',',',')
row[1] = row[1].replace(',',',')
row[4] = row[4].replace(',',',')
writer.writerow(row)
wf.flush()
虽然只是简单的字符串替换,但是依然吃光CPU,然后替换完了,再导入这个文件,这个问题自然就解决了...
2019-12-17 更新,标题和内容全部都替换了,但是依然出现了截断问题.
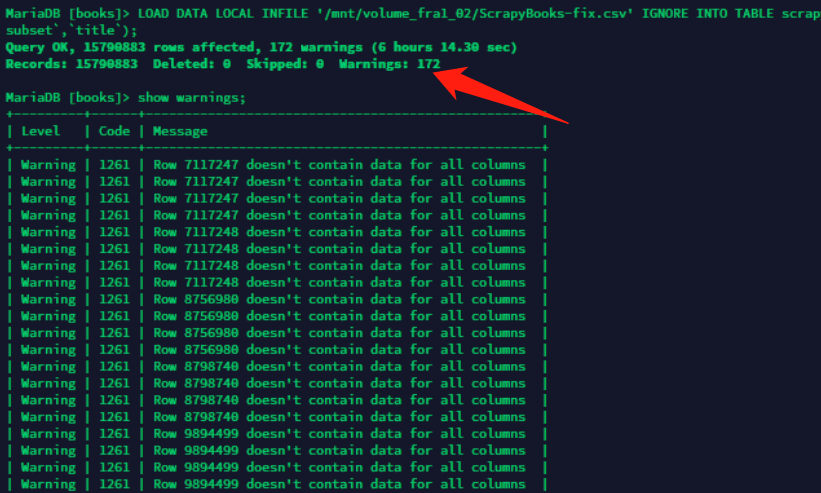
根据下面推断,应该有40多篇文章是出现错误的,每个WARNING大概显示4次,172/4=43篇.
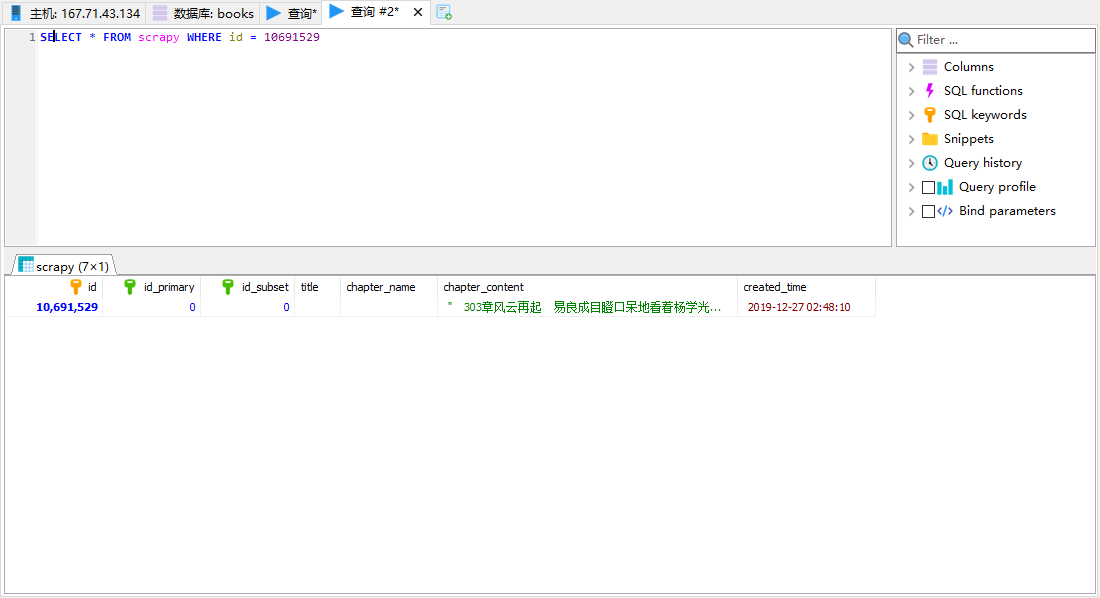
再观察.
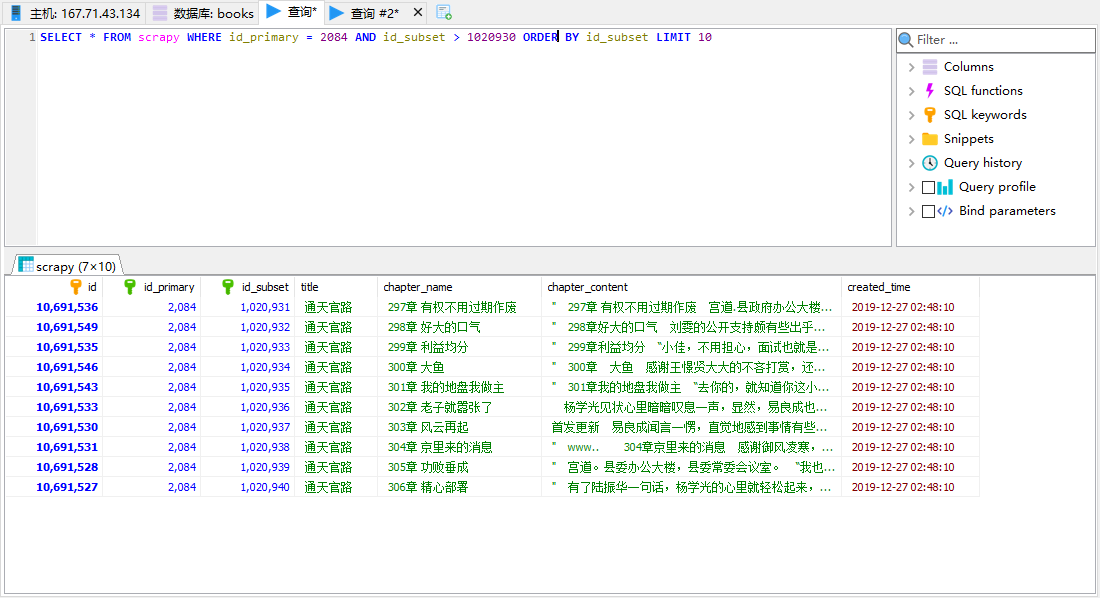
303章是存在的,那是什么原因导致二次入库呢?这个二次入库是否影响提取呢?如果不影响二次提取,这就是个可以忽略的警告,否则就要处理它,首先发现同是303章,内容不一样.
经过和源站对比,实际内容是采集错误的部分 + 采集正确部分拼起来才对.
分割点正是我高亮的字符...

原来是被"号分割了.. 同时被#13,#10这个换行符分割了.
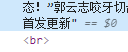
只好分号也一起换了.
import csv
import sys
csv.field_size_limit(sys.maxsize)
with open('./ScrapyBooks-all.csv', newline='', encoding='utf-8') as f,open('./ScrapyBooks-new.csv', 'w', newline='', encoding='utf-8') as wf:
reader = csv.reader(f)
writer = csv.writer(wf)
for row in reader:
row[0] = row[0].replace(',',',').replace('"','').replace('\r\n','')
row[1] = row[1].replace(',',',').replace('"','').replace('\r\n','')
row[4] = row[4].replace(',',',').replace('"','').replace('\r\n','')
writer.writerow(row)
wf.flush()
[…] CSV导入MySQL数据库被意外截断解决 […]