之前是用现有模型进行的,现在开始训练自己的模型,训练模型其实毫无难度,难度是人力成本,具体转到连接:
https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/audio/simple_audio.ipynb当然如果你想不开,非要本机训练,CPU状态下要2-3小时,而Colab提供的GPU加速,只需要十几分钟,而且,默认打开就是使用GPU训练的,当然,我们还不用特殊设置,直接就好用.
读到现在,当然假设大家都已经掌握TF的基础(如果还不行就翻之前的内容),我就大致说一下这个训练中关键的内容.
- 下载 mini_speech_commands.zip 文件,这个文件包含了8个词,每个词都有1000个文件,是不同的1000个人说的.我们要训练的词,也必须找很多人不断录音哦.同理,如果你要训练小狗这个图片模型,也是需要找很多不同形态的小狗,不同环境下的小狗.
- 然后切割数据为三份,训练数据6400,测试数据800,验证数据800,后续用from_tensor_slices分割.
- 获取每个文件对应的label,目录路径中就包含label这么关键的信息.
- 随机抽一些音频数据画图(可视化看看)
- 使用SFFT进行时域转频域(即频谱图),然后后面也打印一些频域图.
- 然后开始训练(构造层啊各种,这些需要不断组合做出最佳结果)
- 然后一直训练到自己合适的loss,然后结束训练.
- 然后用测试验证数据测试一下结果.
不过Colab始终有12小时的限制,如果模型很大,就必须本地训练,可以在本地这么训练.
bazel run tensorflow/examples/speech_commands:train觉得资源不够可以选择性训练.
bazel run tensorflow/examples/speech_commands:train -- --data_dir=my_wavs --wanted_words=up,down训练过程会占用大量CPU/GPU(如果你有使用GPU加速),这里建议如果本地资源不够可以考虑付费VPS(独占CPU,按时长计费那些!)
如果觉得无聊,可以开个tensorboard娱乐下,功能挺多,需要自己探索下.
tensorboard --logdir /tmp/retrain_logs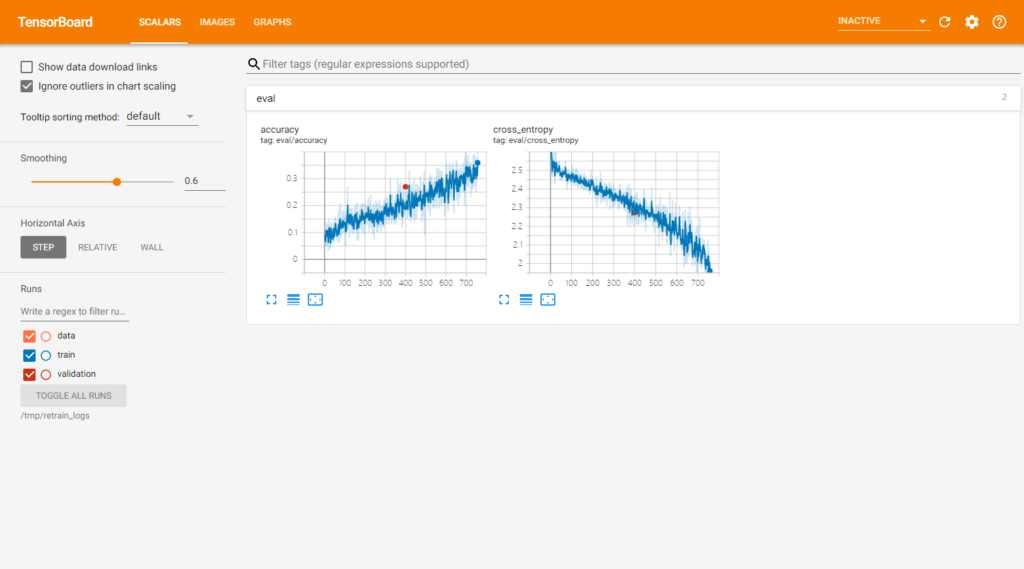
最后得到以下有用文件(其他文件省略了!):
root@ip-tl-ml:~# ls /tmp
speech_commands_train retrain_logs speech_dataset得到模型之后可以转换模型.(start_checkpoint替换成你自己的实际路径!)
bazel run tensorflow/examples/speech_commands:freeze -- --model_architecture=tiny_conv --window_stride=20 --preprocess=micro --wanted_words="yes,no" --output_file=/tmp/tiny_conv.pb --start_checkpoint=/tmp/speech_commands_train/conv.ckpt-18000
最后得到PB文件.
Use `tf.compat.v1.graph_util.extract_sub_graph`
INFO:tensorflow:Saved frozen graph to /tmp/tiny_conv.pb
I0510 05:15:03.693924 139953678481216 freeze.py:173] Saved frozen graph to /tmp/tiny_conv.pb默认toco版本很低,所以使用源码自带的.(必须版本匹配才能转换)
bazel run tensorflow/lite/toco:toco -- --input_file=/tmp/tiny_conv.pb --output_file=/tmp/tiny_conv.tflite --input_shapes=1,49,40,1 --input_arrays=Reshape_2 --output_arrays='labels_softmax' --inference_type=QUANTIZED_UINT8 --mean_values=0 --std_values=9.8077最终得到TFLite模型文件,然后就可以用了,当然也可以用saved_model方法,是目前推荐的方法.
PS:要想训练自己的模型,就去找不同的人去做很多很多的录音文件,然后放在训练目录内,并给上标签,这里也提供了一个不错的工具,也是谷歌训练Speech Commands dataset用的工具,他的地址是:https://github.com/petewarden/open-speech-recording (训练模型的难度在于如何找更多的样本!)
使用saved_model方法保存,转换方法:
bazel run tensorflow/examples/speech_commands:train -- --data_dir=my_wavs --wanted_words=up,down
bazel run tensorflow/examples/speech_commands/freeze -- \
--sample_rate=16000 --dct_coefficient_count=40 --window_size_ms=20 \
--window_stride_ms=10 --clip_duration_ms=1000 \
--model_architecture=conv \
--start_checkpoint=/tmp/speech_commands_train/conv.ckpt-18000 \
--output_file=/tmp/saved_model --save_format=saved_model然后使用Python脚本转换(比如我训练的是从github最新版本代码开始的,所以按照的tf也是每夜构建版,版本才对的上):
converter = tf.lite.TFLiteConverter.from_saved_model("/tmp/saved_model")
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS,tf.lite.OpsSet.SELECT_TF_OPS]
tflite_model = converter.convert()
open("converted_model.tflite", "wb").write(tflite_model)
模型大小:1183344 (依然很大,想缩小可以换INT8量化,需要提取一些代表性数据,精度也有一定的损失,大小差不多可以缩小8 ~ 40倍.)
再再实在搞不懂,就看官方执行例子,只但是官方例子是TF 1.X的,具体猛戳:GitHub