众多教材都是先跟你说什么是CUDA,它怎么原理,它怎么回事,不,这太复杂了,说简单点,就是一个并行计算引擎.
最简单的程序是怎样的?我们反过来,先看程序后看图.
__global__ void testKernel(int val)
{
// blockIdx = 传进去的dimGrid
// threadIdx = 传进去的dimBlock
printf("blockIdx = %d/%d/%d,threadIdx = %d/%d/%d\n", blockIdx.x, blockIdx.y, blockIdx.z, threadIdx.x, threadIdx.y, threadIdx.z);
}
int main(int argc, char **argv)
{
// 配置核并执行.
dim3 dimGrid(5, 5, 5);
dim3 dimBlock(5, 5, 5);
testKernel<<<dimGrid, dimBlock>>>(10);
cudaDeviceSynchronize();
return EXIT_SUCCESS;
}
__global__修饰的一般情况下表示在Host调用,在Device执行,那么这个程序执行了多少次呢?答案是5^6次,即15625次,而这些,是尽可能并行地执行的,那数值可以设置多大具体还得看deviceQuery (一个示例程序),比如我的GPU参数是:
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)当然实际上不一定要用三个维度,也可以写成这样:
__global__ void testKernel(int val)
{
// blockIdx = 传进去的dimGrid
// threadIdx = 传进去的dimBlock
printf("blockIdx = %d,threadIdx = %d/%d/%d\n", blockIdx.x, threadIdx.x, threadIdx.y, threadIdx.z);
}
int main(int argc, char **argv)
{
// 配置核并执行.
dim3 dimGrid(3);
dim3 dimBlock(2, 2, 2);
testKernel<<<dimGrid, dimBlock>>>(10);
cudaDeviceSynchronize();
return EXIT_SUCCESS;
}
返回结果 (部分注释):
blockIdx = 1,threadIdx = 0/0/0 # blockIdx源于dimGrid,属于批次,批次内顺序不可控,显得有规律纯粹巧合.(并行程度取决于SM数量.)
blockIdx = 1,threadIdx = 1/0/0
blockIdx = 1,threadIdx = 0/1/0
blockIdx = 1,threadIdx = 1/1/0
blockIdx = 1,threadIdx = 0/0/1
blockIdx = 1,threadIdx = 1/0/1
blockIdx = 1,threadIdx = 0/1/1
blockIdx = 1,threadIdx = 1/1/1
blockIdx = 2,threadIdx = 0/0/0
blockIdx = 2,threadIdx = 1/0/0
blockIdx = 2,threadIdx = 0/1/0
blockIdx = 2,threadIdx = 1/1/0
blockIdx = 2,threadIdx = 0/0/1
blockIdx = 2,threadIdx = 1/0/1
blockIdx = 2,threadIdx = 0/1/1
blockIdx = 2,threadIdx = 1/1/1
blockIdx = 0,threadIdx = 0/0/0
blockIdx = 0,threadIdx = 1/0/0
blockIdx = 0,threadIdx = 0/1/0
blockIdx = 0,threadIdx = 1/1/0
blockIdx = 0,threadIdx = 0/0/1
blockIdx = 0,threadIdx = 1/0/1
blockIdx = 0,threadIdx = 0/1/1
blockIdx = 0,threadIdx = 1/1/1所以到现在就理解了吧,就是把一小段程序丢到GPU并行处理一下.
现在再看这个图是不是就简单很多了.
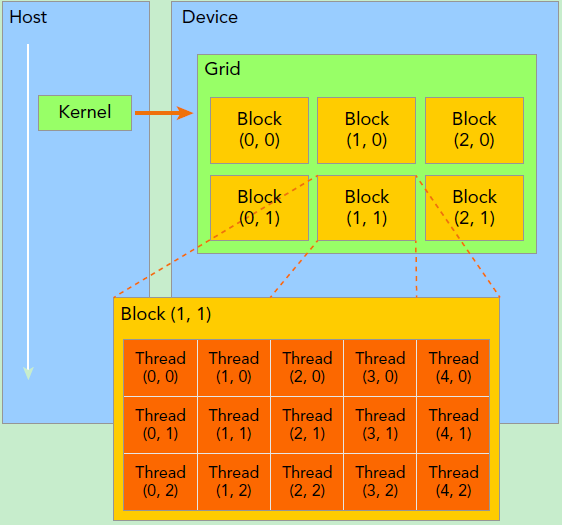
当然如果数据不能来回GPU/CPU,计算也没用,所以必须可以来回啊.
__global__ void testKernel(int* x, int* y, int* z)
{
// blockIdx = 传进去的dimGrid
//
// threadIdx = 传进去的dimBlock
int i = threadIdx.x;
z[i] = x[i] + y[i];
}
int main(int argc, char **argv)
{
int x[10], y[10], z[10];
// 生成测试数据
for (int i = 0; i < 10; i++) {
z[i] = 0;
x[i] = y[i] = i;
}
// 生成GPU内存
int * d_x, * d_y, * d_z;
cudaMalloc((void**)&d_x, 10 * sizeof(int));
cudaMalloc((void**)&d_y, 10 * sizeof(int));
cudaMalloc((void**)&d_z, 10 * sizeof(int));
cudaMemcpy((void*)d_x, (void*)x, 10 * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy((void*)d_y, (void*)y, 10 * sizeof(int), cudaMemcpyHostToDevice);
// 配置核并执行.
dim3 dimGrid(1);
dim3 dimBlock(10);
testKernel<<<dimGrid, dimBlock>>>(d_x, d_y, d_z);
cudaDeviceSynchronize();
cudaMemcpy((void*)z, (void*)d_z, 10 * sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < 10; i++) {
printf("z = %d\n",z[i]);
}
// 正确做法是释放内存,不过我懒得写了.
return EXIT_SUCCESS;
}
结果显然是计算每一个z[n]=x[n]+y[n],但是这样并行程度不够,改成Grid/Block都有部分.
#define NSIZE 4096
__global__ void testKernel(uint64_t* x, uint64_t* y, uint64_t* z)
{
// blockIdx = 传进去的dimGrid
//
// threadIdx = 传进去的dimBlock
int i = gridDim.x * threadIdx.x + blockIdx.x;
z[i] = x[i] + y[i];
}
int main(int argc, char **argv)
{
uint64_t x[NSIZE], y[NSIZE], z[NSIZE];
// 生成测试数据
for (int i = 0; i < NSIZE; i++) {
z[i] = 0;
x[i] = y[i] = i + 1;
}
// 生成GPU内存
uint64_t* d_x, * d_y, * d_z;
cudaMalloc((void**)&d_x, NSIZE * sizeof(uint64_t));
cudaMalloc((void**)&d_y, NSIZE * sizeof(uint64_t));
cudaMalloc((void**)&d_z, NSIZE * sizeof(uint64_t));
cudaMemcpy((void*)d_x, (void*)x, NSIZE * sizeof(uint64_t), cudaMemcpyHostToDevice);
cudaMemcpy((void*)d_y, (void*)y, NSIZE * sizeof(uint64_t), cudaMemcpyHostToDevice);
// 配置核并执行.
dim3 dimGrid(256); // gridDim.x = 256
dim3 dimBlock((NSIZE + dimGrid.x - 1) / dimGrid.x); // blockDim.x = NSIZE / gridDim.x = 16
testKernel<<<dimGrid, dimBlock>>>(d_x, d_y, d_z);
cudaDeviceSynchronize();
cudaMemcpy((void*)z, (void*)d_z, NSIZE * sizeof(uint64_t), cudaMemcpyDeviceToHost);
for (int i = 0; i < NSIZE; i++) {
printf("z = %d\n", z[i]);
}
cudaFree(x);
cudaFree(y);
cudaFree(z);
return EXIT_SUCCESS;
}做矩阵加法比CPU方便更多.
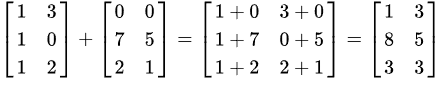
每个元素是分开的,那么,Cuda入门就算完成了,不过,基础知识可没补好,带着疑问去解决其他问题.
1)一个SM可以执行多少线程? (和很多因素有关)
2)其他函数修饰符有哪些?
3)还有哪些API?