不得不吐槽下,资料是真的少,手册也有些地方说的摸棱两可,其中我最不解的是DMA中Ring的设置,压根也没说Ring是什么,估计是环形缓冲区的某个控制.
手册里没有明确说是个什么东西,也没图示,只有短短一句话.

Size of address wrap region. If 0, don’t wrap. For values n>0, only the lower n bits of the address will change. This wraps the address on a (1 << n) byte boundary, facilitating access to naturally-aligned ring buffers.
Ring sizes between 2 and 32768 bytes are possible. This can apply to either read or write addresses, based on value of RING_SEL.
0x0 → RING_NONE
地址包覆区域的大小。如果是0,则不包裹。对于n>0的值,只有地址的低n位会改变。这 在一个(1<n)字节的边界上包裹地址,有利于 访问自然对齐的环形缓冲区。
环的大小在2到32768字节之间是可能的。这 可以适用于读或写地址,基于 RING_SEL的值。
0x0 → RING_NONE函数分为对写地址环绕或对读地址环绕.
Set address wrapping parameters in a channel configuration object.
Size of address wrap region. If 0, don’t wrap. For values n > 0, only the lower n bits of the address will change. This wraps the address on a (1 << n) byte boundary, facilitating access to naturally-aligned ring buffers. Ring sizes between 2 and 32768 bytes are possible (size_bits from 1 - 15)
0x0 -> No wrapping.
Parameters
c Pointer to channel configuration object
write True to apply to write addresses, false to apply to read addresses
size_bits 0 to disable wrapping. Otherwise the size in bits of the changing part of the address. Effectively wraps the address on a (1 << size_bits) byte boundary.
还是用官方例子说明.
代码地址:https://github.com/raspberrypi/pico-examples/blob/master/dma/control_blocks/control_blocks.c
dma_channel_config c = dma_channel_get_default_config(ctrl_chan);
channel_config_set_transfer_data_size(&c, DMA_SIZE_32);
channel_config_set_read_increment(&c, true);
channel_config_set_write_increment(&c, true);
channel_config_set_ring(&c, true, 3); // 1 << 3 byte boundary on write ptr
dma_channel_configure(
ctrl_chan,
&c,
&dma_hw->ch[data_chan].al3_transfer_count, // Initial write address
&control_blocks, // Initial read address
2, // Halt after each control block
false // Don't start yet
);其中data_chan = 1,那么al3_transfer_count是0x50000064,写入两个32位后,即在他基础上移动8个字节,所以ring的wrap边界是8字节,再下一个就会环回到0x50000064,继续每一次搬运+4字节(根据设置).
但是,这里面有坑,下面来分析一下这个功能,这里做一个实验,删除了一些闲杂的信息,先做第一步实现.
#include <stdio.h>
#include "pico/stdlib.h"
#include "hardware/dma.h"
#include "hardware/structs/uart.h"
const char word0[] = "ABCDEFGH";
const uint32_t len = count_of(word0) - 1;
int main() {
stdio_init_all();
uart_init(uart0, 9600);
gpio_set_function(0 /* UART_TX_PIN */, GPIO_FUNC_UART);
gpio_set_function(1 /* UART_RX_PIN */, GPIO_FUNC_UART);
puts("DMA control block example:");
int ctrl_chan = dma_claim_unused_channel(true);
int data_chan = dma_claim_unused_channel(true);
dma_channel_config c = dma_channel_get_default_config(ctrl_chan);
channel_config_set_transfer_data_size(&c, DMA_SIZE_32);
channel_config_set_read_increment(&c, false); // 因为就一个地址永远地写到同一个位置,目的是循环触发同一个DMA.
channel_config_set_write_increment(&c, false);
dma_channel_configure(
ctrl_chan,
&c,
&dma_hw->ch[data_chan].al1_transfer_count_trig,
&len,
1,
false
);
c = dma_channel_get_default_config(data_chan);
channel_config_set_transfer_data_size(&c, DMA_SIZE_8);
channel_config_set_dreq(&c, uart_get_dreq(uart_default, true));
channel_config_set_chain_to(&c, ctrl_chan); // 当数据DMA传输完成就回到控制DMA传输,控制DMA又因为写Trigger,会发起数据DMA传输,循环往复.
channel_config_set_irq_quiet(&c, true);
channel_config_set_ring(&c, false, 3); // 环回边界是8个字节(刚好buf就是8个字节.)
channel_config_set_read_increment(&c, true); // 读地址是递增的,但是到ring wrap时候会返回.
channel_config_set_write_increment(&c, false);
dma_channel_configure(
data_chan,
&c,
&uart_get_hw(uart_default)->dr,
&word0,
0,
false
);
dma_start_channel_mask(1u << ctrl_chan); // 开始传输
while (!(dma_hw->intr & 1u << data_chan))
tight_loop_contents();
dma_hw->ints0 = 1u << data_chan;
puts("DMA finished.");
}然后运行后发现只循环输出.ABCD,循环输出这个,为什么呢,分析一下,首先看word0地址.
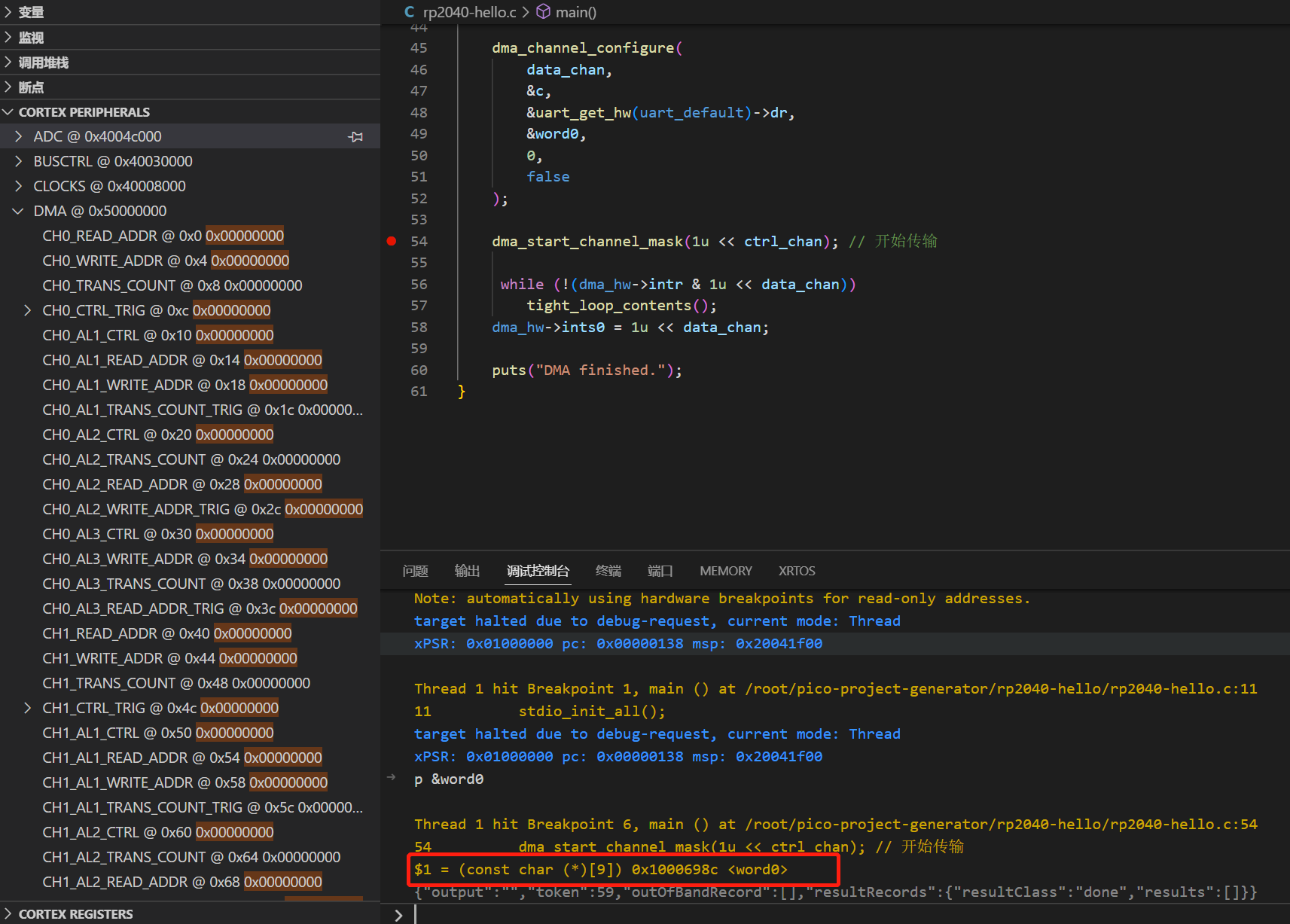
0x1000698c的ring wrap 3bit就是从范围0x10006988-0x1000698f,没法理解的看计算器.
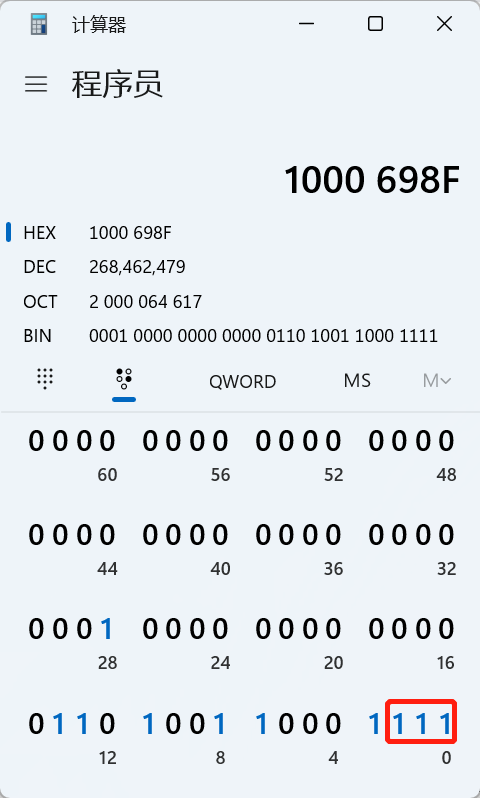
很不幸,实际输出结果就是0x46,0x00,0x00,0x00,'A','B','C','D',而0x00不可见,所以串口上也看不到.这样能理解ring wrap了吧,那么如何修正这个问题.只需要对齐word0就行.
const char word0[] __attribute__((aligned(8))) = "ABCDEFGH";但是说实话,用这个来实现循环发送有一个局限性,buf必须2^n个大小,如果不是,那又怎么办呢.我想,级联多个DMA控制块应该是可以实现的,ctrl1控制ctrl2,让ctrl2每次从同一个buf里取数据,ctrl2实际控制data dma,这样等于每次重新填写data dma,自然一切问题都不是问题了,至于效率嘛,释放了CPU还不够嘛?