这个只有1个文件,不足1K LUT6就能实现的内核,由YosysHQ大神开发,其中Yosys,Nextpnr这些都是大神的作品,可谓是对这方面特别了解,这个内核重点不是性能,而是节约.甚至是考虑设计为某些主处理器的协处理器,整个内核只有一个文件,整体就只有几个模块,并且整个CPU都是可配置的.
项目地址:https://github.com/YosysHQ/picorv32
// The PicoRV32 CPU implementation
module picorv32
// ...
endmodule
module picorv32_regs
// ...
endmodule
// A PCPI core that implements the MUL[H[SU|U]] instructions
module picorv32_pcpi_mul
// ...
endmodule
// A version of picorv32_pcpi_fast_mul using a single cycle multiplier
module picorv32_pcpi_fast_mul
// ...
endmodule
// A PCPI core that implements the DIV[U]/REM[U] instructions
module picorv32_pcpi_div
// ...
endmodule
// The version of the CPU with AXI4-Lite interface
module picorv32_axi
// ...
endmodule
// Adapter from PicoRV32 Memory Interface to AXI4-Lite
module picorv32_axi_adapter
// ...
endmodule
// The version of the CPU with Wishbone Master interface
module picorv32_wb
// ...
endmodule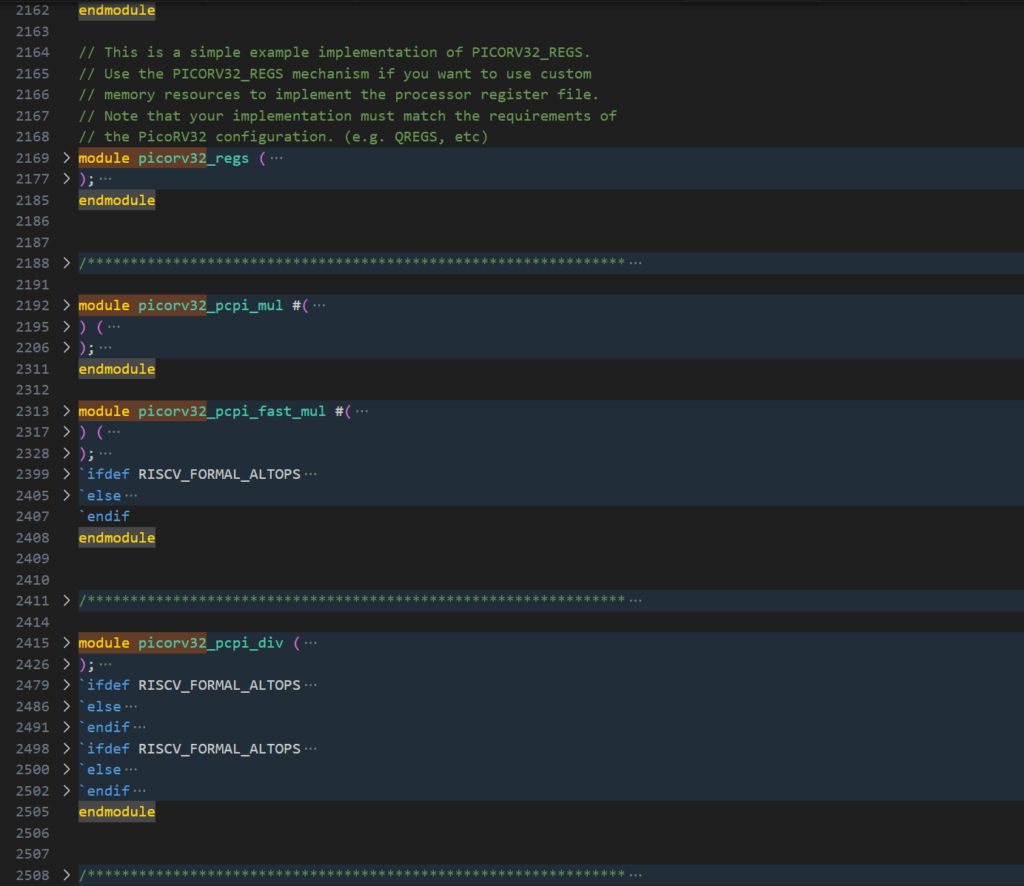
先第一步从Memory Interface开始分析,发现他也是5组功能.
reg [1:0] mem_state;
reg [1:0] mem_wordsize;
reg [31:0] mem_rdata_word;
reg [31:0] mem_rdata_q;
// 一大堆有用的定义和wire
always @(posedge clk) begin
// 复位信号
end
always @* begin
// 具体读写操作落实,L1860-L1862决定.
end
always @(posedge clk) begin
// 压缩指令的解压
end
always @(posedge clk) begin
// 一些断言,没有做实际功能.
end
always @(posedge clk) begin
// 取指令/写入状态机
end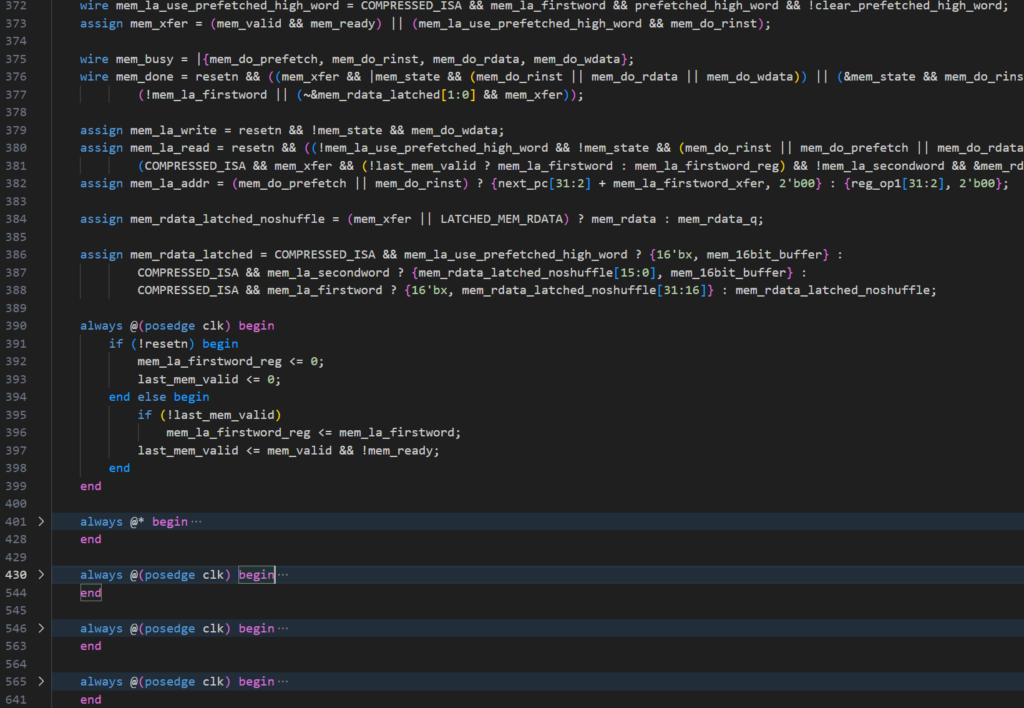
可以看到写的时候同时进行读.
always @* begin
(* full_case *)
case (mem_wordsize)
0: begin
mem_la_wdata = reg_op2;
mem_la_wstrb = 4'b1111;
mem_rdata_word = mem_rdata;
end
1: begin
mem_la_wdata = {2{reg_op2[15:0]}};
mem_la_wstrb = reg_op1[1] ? 4'b1100 : 4'b0011;
case (reg_op1[1])
1'b0: mem_rdata_word = {16'b0, mem_rdata[15: 0]};
1'b1: mem_rdata_word = {16'b0, mem_rdata[31:16]};
endcase
end
2: begin
mem_la_wdata = {4{reg_op2[7:0]}};
mem_la_wstrb = 4'b0001 << reg_op1[1:0];
case (reg_op1[1:0])
2'b00: mem_rdata_word = {24'b0, mem_rdata[ 7: 0]};
2'b01: mem_rdata_word = {24'b0, mem_rdata[15: 8]};
2'b10: mem_rdata_word = {24'b0, mem_rdata[23:16]};
2'b11: mem_rdata_word = {24'b0, mem_rdata[31:24]};
endcase
end
endcase
end其中这里用到的是SB(Byte),SH(Half Word),SW(Word)是在1860行给出的.

其中instr_sb这些是通过线与来确定的,有兴趣的自己跟一下代码就知道,这里不展开.
既然获得了指令,当然也要对指令进行解释,其中有一个大区快Instruction Decoder就是用来干这个活的.里面有几个关键的变量.
reg [regindex_bits-1:0] decoded_rd, decoded_rs1, decoded_rs2;
reg [31:0] decoded_imm, decoded_imm_j;如果不考虑压缩指令,那么他们在mem_done(位于之前的Memory Interface)完成时,且为指令,则立即能解码出结果.
decoded_rd <= mem_rdata_latched[11:7];
decoded_rs1 <= mem_rdata_latched[19:15];
decoded_rs2 <= mem_rdata_latched[24:20];而立即数存在多种情况,所以会在后面单独赋值.
(* parallel_case *)
case (1'b1)
instr_jal:
decoded_imm <= decoded_imm_j;
|{instr_lui, instr_auipc}:
decoded_imm <= mem_rdata_q[31:12] << 12;
|{instr_jalr, is_lb_lh_lw_lbu_lhu, is_alu_reg_imm}:
decoded_imm <= $signed(mem_rdata_q[31:20]);
is_beq_bne_blt_bge_bltu_bgeu:
decoded_imm <= $signed({mem_rdata_q[31], mem_rdata_q[7], mem_rdata_q[30:25], mem_rdata_q[11:8], 1'b0});
is_sb_sh_sw:
decoded_imm <= $signed({mem_rdata_q[31:25], mem_rdata_q[11:7]});
default:
decoded_imm <= 1'bx;
endcase其他就是判断指令具体是哪一条了,这里就贴出部分,更多自己看看源码吧.
instr_lb <= is_lb_lh_lw_lbu_lhu && mem_rdata_q[14:12] == 3'b000;
instr_lh <= is_lb_lh_lw_lbu_lhu && mem_rdata_q[14:12] == 3'b001;
instr_lw <= is_lb_lh_lw_lbu_lhu && mem_rdata_q[14:12] == 3'b010;
instr_lbu <= is_lb_lh_lw_lbu_lhu && mem_rdata_q[14:12] == 3'b100;
instr_lhu <= is_lb_lh_lw_lbu_lhu && mem_rdata_q[14:12] == 3'b101;如果遇压缩指令,那就要像储存解释压缩指令一样,按照压缩指令的压缩方法进行指令解压,举个例子,C.LW对应的长指令LW是有一点点的不同的.
其中rs1变成8+rs1',所以得出decoded_rs1 <= 8 + mem_rdata_latched[9:7],又rd变成8+rd',所以decoded_rd <= 8 + mem_rdata_latched[4:2]也很好理解.最后标记他为Load相关指令就搞定了.
case (mem_rdata_latched[15:13])
3'b000: begin // C.ADDI4SPN
is_alu_reg_imm <= |mem_rdata_latched[12:5];
decoded_rs1 <= 2;
decoded_rd <= 8 + mem_rdata_latched[4:2];
end
3'b010: begin // C.LW
is_lb_lh_lw_lbu_lhu <= 1;
decoded_rs1 <= 8 + mem_rdata_latched[9:7];
decoded_rd <= 8 + mem_rdata_latched[4:2];
end
3'b110: begin // C.SW
is_sb_sh_sw <= 1;
decoded_rs1 <= 8 + mem_rdata_latched[9:7];
decoded_rs2 <= 8 + mem_rdata_latched[4:2];
end
endcase

指令解码好了总的执行吧,执行这件事由主状态机(Main State Machine)来完成.在cpu_state_ld_rs1阶段,当指令为Load(is_lb_lh_lw_lbu_lhu)并且不是非法指令(instr_trap == 0,即这个指令是有启用的).进行解开操作.
`debug($display("LD_RS1: %2d 0x%08x", decoded_rs1, cpuregs_rs1);)
reg_op1 <= cpuregs_rs1;
dbg_rs1val <= cpuregs_rs1;
dbg_rs1val_valid <= 1;
cpu_state <= cpu_state_ldmem;
mem_do_rinst <= 1;下一步状态机会走到cpu_state_ldmem,这不巧妙地告诉你状态机如何流动了吗?先判断指令是什么,再决定下一个状态是什么.比如ldmem这个状态,进去后就会判断目前内存接口是不是在读取,不是的话就可以发起下一个读取需求了,具体读取过程基本就是赋值mem_wordsize,如果不是整Word还要考虑op1,写完的话,会重新回到一开始状态(fetch),大概就是这样,不过这里大量用到parallel_case,在mem_do_prefetch = 0且mem_done = 1时,会同时进入两个分支,另外mem_do_prefetch是在主状态机赋值的,只要不是JALR和RETIRQ都为真,那么这个就是0.所以当内存不done时候请求读,当内存done当然就返回了.
cpu_state_ldmem: begin
latched_store <= 1;
if (!mem_do_prefetch || mem_done) begin
if (!mem_do_rdata) begin
(* parallel_case, full_case *)
case (1'b1)
instr_lb || instr_lbu: mem_wordsize <= 2;
instr_lh || instr_lhu: mem_wordsize <= 1;
instr_lw: mem_wordsize <= 0;
endcase
latched_is_lu <= is_lbu_lhu_lw;
latched_is_lh <= instr_lh;
latched_is_lb <= instr_lb;
if (ENABLE_TRACE) begin
trace_valid <= 1;
trace_data <= (irq_active ? TRACE_IRQ : 0) | TRACE_ADDR | ((reg_op1 + decoded_imm) & 32'hffffffff);
end
reg_op1 <= reg_op1 + decoded_imm;
set_mem_do_rdata = 1;
end
if (!mem_do_prefetch && mem_done) begin
(* parallel_case, full_case *)
case (1'b1)
latched_is_lu: reg_out <= mem_rdata_word;
latched_is_lh: reg_out <= $signed(mem_rdata_word[15:0]);
latched_is_lb: reg_out <= $signed(mem_rdata_word[7:0]);
endcase
decoder_trigger <= 1;
decoder_pseudo_trigger <= 1;
cpu_state <= cpu_state_fetch;
end
end
end现在主框架剩下一个大的状态机了,总结下来有这么几个状态.
- fetch => 这是CPU的初始状态,在此状态下,CPU 的目标是从内存中获取下一条指令.这一阶段可能需要多个周期,因为我们必须等待内存返回.一旦指令被读取并解码,状态将转入 Id_rs1.
- Id_rs1 => 该状态专用于读取寄存器值,实际上有两个状态与寄存器值有关,另一个是 Id_rs2,为寄存器值设置两个状态的原因是某些寄存器文件可能不支持双端口,因此它不能在同一周期读取两个寄存器的值.(我猜的!),获得寄存器值后.我们将进入以下状态之一(ldmem,stmem,exec,shift),这取决于解码后的指令类型.
- Id_rs2 => 参考ld_rs1.
- ldmem => 内存读取相关指令.
- stmem => 内存写入相关指令.
- exec => 主要进行 ALU 运算,收集计算结果并将其放入另一个寄存器.
- shift => 由于某种原因,Shift 状态与执行状态被分开,这可能与 TWO_STAGE_SHIFT 模块参数有关,该参数将使 CPU 用两个周期完成一次移位操作,这样做可能是为了减少电路的最长路径?
这样主体框架已经完成了,至于PCPI,AXI各种warpper,相信看着代码稍微分析也一点都不难.
带佬流啤!话说这种内核写完之后,如何测试呢?
@lagramoon 可以参考我上一篇的内容.